
写在前面:最近读到 Uber 实时处理管道的演进历程,想推荐给大家。这篇文章最打动我的地方,是它把一个 system design 题目从纸面带到了现实。我们准备面试时反复练习"如何设计一个实时数据管道",答案却往往停留在画框图、列组件;而这篇文章呈现的是:当业务方同时要求低延迟和高准确性时,工程师真正纠结的是什么、最后放弃了什么、又如何说服自己和团队接受这个取舍。读完之后,我对"trade-off"这个词的理解比从前具体了很多。所以我们来具体看一下
Uber 原本有什么?
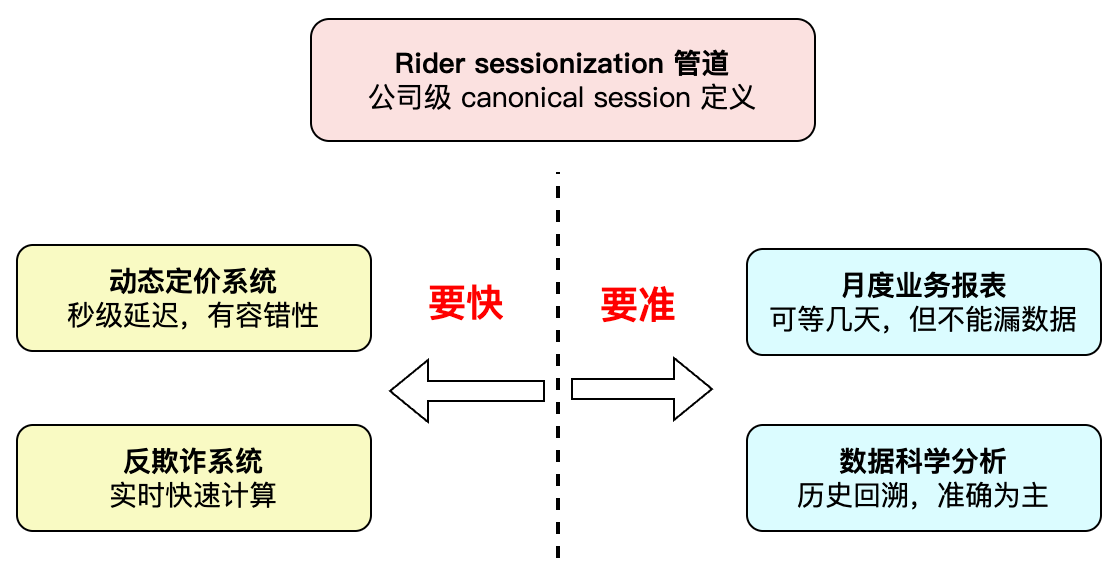
在Uber的底层数据流中, 有一条非常核心的流处理管道: rider sessionization(乘客会话化)。它的作用是把一个乘客的一连串行为(打开 app、查价、下单、取消、评价……)按“一次会话”切分打包。最初这条管道是为 Uber 的动态定价系统服务的,给动态定价模型提供低延迟的建模特征。
很快公司的其他团队发现这个 “session” 的定义非常好用,反欺诈团队、用户行为分析团队、做月度业务报表的数据科学家全都来接入这份数据,把它当成了公司级的 canonical session 数据源。
为什么要升级?
一个管道被这么多团队共用,问题就出现了:不同下游对延迟和正确性的要求完全矛盾。
一类下游要快——秒级分析,算错一点、漏一点没关系,反正下一秒会更新;
另一类下游要准——月度业务报表,可以等几天才出,但数据必须完整,漏一条都是 bug。
而流处理天生就是在“快”和“准”之间做取舍的。
事件不会严格按时间顺序到达——乘客可能下次打开 app 才去评价上次的司机,客户端日志可能因为网络几小时后才上传。问题是:流处理要一直往前算,不能永远等下去。所以它必须定一个规矩:
“我等到 9:05 分为止。9:05 之前发生的事件,只要在 9:05 之前到达,我都算进来;9:05 一过,我就认为 9:00 这个时间段的数据已经齐了,开始出结果。之后再有迟到的 9:00 事件进来,对不起,直接丢掉。”
这个“我等到什么时候为止”的截止线,就是所谓的 watermark。
这么做的好处是系统永远不卡、延迟可控;代价是迟到的数据会被静默丢弃。对定价、秒级分析这种下游来说,丢一点无所谓,反正下一秒会刷新;但对要出月度报表的下游来说,丢一条就是一条 bug。
所以 Uber 需要一条 backfill 管道:过几天之后,回头把当时漏掉、算错的数据重新算一遍。
