


第一章:本质与宏观架构 (The Big Picture)
1.1 别再叫它“消息队列”
在数据工程的视角里,请把 Kafka 定义为:分布式提交日志 (Distributed Commit Log)。
- 传统 MQ (RabbitMQ):是“邮箱”。把信取走,信就没了。它关注的是“传递”。
- Kafka:是“账本”。不管你看不看,账(数据)都追加在那,不可变。它关注的是“存储”和“流”。
这个本质决定了:Kafka 的数据是落地生根的,是等着你去“拉”的,而不是塞给你的。
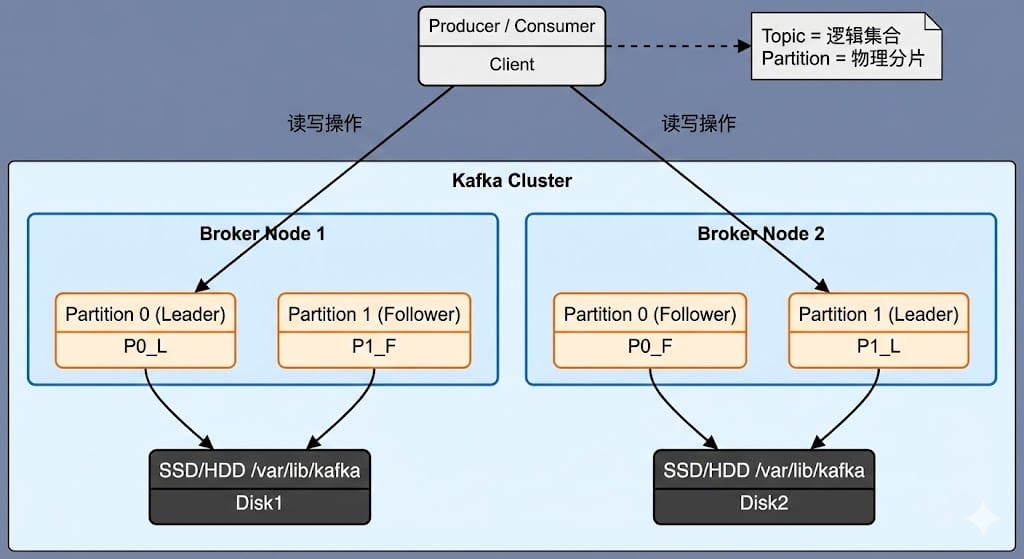
1.2 架构拓扑图
Topic 只是个逻辑皮囊,Partition 才是物理骨架。
1.3 为什么选 Kafka?
| 特性 | RabbitMQ / ActiveMQ | Apache Kafka | 评论 |
|---|---|---|---|
| 存储模型 | 内存为主, 消费即删。 |
磁盘 Commit Log, 持久化存储。 |
Kafka 是为了“大数据存储”而生的,RabbitMQ 只是个“传话筒”。 |
| 数据结构 | 复杂的路由 (Exchange/Queue)。 |
简单的追加写日志 (Append Only Log)。 |
越简单,越耐造。 复杂路由在大数据量下就是灾难。 |
| 吞吐量级 | 万级 TPS。 | 百万级 TPS。 | 架构决定上限。Kafka 是把磁盘当内存用的怪物(顺序写)。 |
| 消费模式 | Broker Push (推)。 | Consumer Pull (拉)。 | 下游处理不过来就慢点拉,天然反压 (Backpressure),这在流计算里是救命的。 |
| 有序性 | 全局有序 (单 Queue)。 |
Partition 内有序。 | 这是面试坑点:Kafka 不保证全局有序! |
第二章:核心原理深度拆解 (Deep Dive)
这一章是本文的核心。我们要深入到文件系统层面。
2.1 逻辑结构 vs 物理结构
很多新手容易混淆 Topic 和 Partition。
- Topic (逻辑):你可以把它理解为数据库里的 Table Name。它只是一个虚拟的集合。
- Partition (物理):这是 Kafka 并发和扩展的基石。
- Sharding(分片):一个 Topic 被切分成多个 Partition,分布在不同的 Broker 上。这使得 Kafka 的吞吐量可以随机器数量线性扩展。
- Concurrency(并发):在 Consumer Group 中,一个 Partition 只能被一个 Consumer 线程消费。记住这句话,这是解决消费积压的关键。
2.2 磁盘上的秘密:目录布局
如果你 SSH 到 Broker 上,进入 log.dirs 配置的目录(比如 /var/lib/kafka/data),你会看到什么?
假设我们有一个 Topic 叫 order_events,有 2 个分区。
/var/lib/kafka/data/
├── cleaner-offset-checkpoint # 日志清理检查点
├── recovery-point-offset-checkpoint # 数据恢复检查点
├── replication-offset-checkpoint # 副本复制检查点
│
├── order_events-0/ # 【分区 0 的物理目录】
│ ├── 00000000000000000000.log # 数据段文件 (Segment)
│ ├── 00000000000000000000.index # 位移索引
│ ├── 00000000000000000000.timeindex # 时间索引
│ ├── 00000000000000000000.snapshot # 幂等性快照
│ └── leader-epoch-checkpoint # 纪元检查点
│
└── order_events-1/ # 【分区 1 的物理目录】
├── ... (同上)2.3 Segment (日志段) 的设计哲学
为什么要有 Segment? 如果 Partition 是一个单一大文件,当你要删除 7 天前的数据时,你得从文件头部开始“剪切”内容,这对文件系统来说是噩梦。
Kafka 的策略是 Rolling (滚动切分):
- 切分条件:当
.log文件大小达到 1GB (默认log.segment.bytes),或者时间过了一周,就会关闭当前文件,新建一个。 - 命名规则:文件名是该段中 第一条消息的 Offset。
- 例如:
00000000000000368769.log表示这个文件里存的第一条消息,Offset 是 368769。
- 例如:
2.4 索引机制详解:.index 与 .timeindex
这是 Kafka 读取速度快的核心秘密之一:稀疏索引 (Sparse Index)。
很多同学以为 Kafka 会为每一条消息建索引,错!那样索引文件会大到内存装不下。Kafka 默认每隔 4KB 数据(log.index.interval.bytes),才写一条索引。
2.4.1 .index 文件内部结构 (Offset Index)
这个文件是二进制的,每一条索引固定 8 字节:
- Relative Offset (4 Bytes):相对位移。
- 小万注:为了省空间,这里存的是
绝对 Offset - Base Offset。比如文件名是 100,这里存 5,代表绝对 Offset 105。
- 小万注:为了省空间,这里存的是
- Physical Position (4 Bytes):物理位置。
- 消息在
.log文件中的字节偏移量。
- 消息在
2.4.2 查找流程 (图解)
假设消费者要找 Offset = 368777 的消息:
sequenceDiagram
participant C as Consumer
participant Broker as Kafka Broker
participant Mem as Memory (SkipList)
participant Disk as Disk Files
C->>Broker: Fetch(Offset=368777)
Broker->>Mem: 1. 二分查找 Segment 列表
Mem-->>Broker: 定位到 00...368769.log
Broker->>Disk: 2. 读取 00...368769.index
Note right of Disk: 使用二分查找 (Binary Search)<br/>找到 <= 368777 的最大索引项
Disk-->>Broker: 返回 [RelOffset=5, Pos=1024] (即绝对Offset 368774)
Broker->>Disk: 3. 打开 00...368769.log
Note right of Disk: fileChannel.position(1024)<br/>从位置 1024 开始顺序扫描
Disk-->>Broker: 扫描几条后,找到 368777,返回数据底层逻辑:通过 “二分查找索引 + 顺序扫描小段日志”,Kafka 将磁盘 I/O 降到了最低,同时保证索引文件足够小,可以常驻 PageCache。
第三章:性能与底层机制 (Kernel Level)
为什么 Kafka 能跑满磁盘带宽?这得从操作系统内核说起。
3.1 磁盘顺序写 (Sequential Write)
这是老生常谈,但必须得懂物理原理。 机械硬盘(HDD)最怕什么?怕 Seek (寻道)。磁头移来移去,时间全浪费在路上了。
- 随机写:吞吐量可能只有几百 KB/s。
- 顺序写:吞吐量可以达到几百 MB/s,甚至超过内存的随机写速度。
Kafka 强制 Append Only。所有的写操作,都是直接追加到文件末尾。这让 Kafka 即使在廉价的 HDD 机器上,也能跑出惊人的性能。
3.2 零拷贝 (Zero Copy) —— sendfile
当 Consumer 来拉数据时,如果用传统的 read + write 系统调用,数据要在 内核态 (Kernel Space) 和 用户态 (User Space) 之间拷贝 4 次,上下文切换 4 次。CPU 都在忙着搬砖。
Kafka 使用 Java 的 FileChannel.transferTo,底层调用 Linux 的 sendfile。
数据流向对比:
| 模式 | 数据路径 | CPU 拷贝 | 上下文切换 |
|---|---|---|---|
| 传统 I/O |
Disk → Kernel Buffer → User Buffer → Socket Buffer → NIC |
2 次 | 4 次 |
| Kafka 零拷贝 | Disk → Kernel Buffer (PageCache) → NIC (网卡) |
0 次 (数据不进 JVM) |
2 次 |
小万划重点:这就是为什么 Kafka 的 Heap Size 不需要设置太大(6GB 够了)。剩下的内存全留给操作系统做 PageCache,这才是 Kafka 的“真·内存”。
3.3 PageCache (页缓存)
Kafka 自己不存缓存,它“寄生”在操作系统的 PageCache 上。
- 写:Producer 发数据 -> 写入 PageCache -> 立马返回 ACK。
- 风险:这时候数据还在内存里,没落盘。如果断电,数据会丢。(进程挂了没事,OS 还在)。
- 读:Consumer 拉数据 -> 优先读 PageCache。
- 爽点:如果消费跟得上生产,数据在内存里转一圈就走了,根本不碰磁盘。
第四章:小万的 Discord 社区实战案例集
🛑 案例 1:分区数太少,Flink 总是背压
- 用户:
@BigData_Joe - 小万诊断: 看了眼 Topic 配置,Partition 只有 5 个。 根因:Kafka 的并行度是锁死在 Partition 上的。你有 5 个 Partition,下游起 100 个线程,其中 95 个都在空转(Idle)。
- 解决: 根据吞吐量估算,将 Partition 扩容到 50 个。(注意:扩容后新数据才会去新分区,老数据不会动,会有短暂的数据倾斜)。
场景:
"小万,上游流量暴涨,我的 Flink 任务并发加到了 100,为什么 Kafka 消费速度还是上不去?监控看 Broker 也没压力啊。"
🛑 案例 2:磁盘满了,说好的保留 24 小时呢?
- 用户:
@DevOps_Mike - 小万诊断: Topic 流量极低,半天才来几条数据。 根因:Kafka 删除是以 Segment 为单位的。默认 Segment 大小是 1GB。因为流量小,这个 Segment 写了一周还没写满 1GB,它就是 Active Segment(活跃段)。 Active Segment 是永远不会被删除的,不管它多老。
- 解决: 调整
log.roll.hours = 24。强制每 24 小时切分一个新文件,让老文件“退役”,这样 Retention 策略才能生效。
场景:
"设置了 log.retention.hours=24,结果磁盘上还有 7 天前的数据,报警了!"🛑 案例 3:离线任务把实时任务搞挂了 (PageCache 污染)
- 用户:
@TechLead_Wang - 小万诊断: 这是典型的 冷读 (Cold Read) 污染。 Spark 拉取 3 天前的数据 -> 这些数据不在内存 -> 触发大量磁盘随机读 -> 操作系统为了缓存这些冷数据,把 PageCache 里的热数据(实时流)挤出去了。 结果就是:实时读写也被迫走磁盘,IO 直接打满。
- 解决:
- 物理隔离:离线任务强制走 Follower Fetching(从副本拉数据,别干扰 Leader)。
- 限流:给离线 Consumer 加上配额限制(Quota)。
场景:
"平时 Kafka 很快,今天有个同事跑了个 Spark 任务拉历史数据,结果整个 Kafka 读写延迟飙升,实时业务报警了。"

