

1. 引言 (Introduction)
1.1 Spark的诞生与演进
在大数据处理的浪潮中,Apache Spark 已成为事实上的标准计算引擎。它最初于2009年在加州大学伯克利分校的AMP实验室诞生,旨在克服传统Hadoop MapReduce框架在迭代计算和交互式数据分析方面的性能瓶颈。MapReduce基于磁盘的计算模型导致了大量的I/O开销,而Spark则通过引入基于内存的计算,将处理速度提升了几个数量级。2014年,Spark成为Apache软件基金会的顶级项目,并凭借其卓越的性能和通用性,迅速发展成为大数据生态的核心。
1.2 为什么选择Spark?—— 核心优势概览
Spark之所以能够脱颖而出,得益于其几大核心优势:
- 运行速度快:通过基于内存的计算,并辅以高效的DAG(有向无环图)执行引擎,Spark在内存中的处理速度可比MapReduce快100倍以上,即使在基于磁盘的计算中也能快10倍。
- 易用性强:Spark提供了丰富的多语言API,支持Scala、Java、Python和R,并内置了超过80种高级算法,极大地简化了开发流程。其交互式Shell(spark-shell、pyspark)也为数据探索和快速原型开发提供了便利。
- 通用性高:Spark是一个统一的分析引擎,其技术栈覆盖了多种大数据应用场景:
- Spark SQL:用于结构化数据处理和交互式查询。
- Spark Streaming:用于实时流数据处理。
- MLlib:用于机器学习。
- GraphX:用于图计算。
- 容错性强:Spark的核心抽象是弹性分布式数据集(RDD)。RDD通过其“血缘关系”(Lineage)记录了数据的转换过程,当某个分区数据丢失时,Spark可以根据血缘关系重新计算,实现高效的容错。
- 可扩展性好:Spark可以与多种存储系统(如HDFS、HBase、Cassandra)和资源管理器无缝集成,支持从单机到数千个节点的集群规模。
1.3 文章目标与内容结构
本文旨在为大数据初学者和从业者系统地揭示Spark的核心架构。我们将深入剖析其三大核心组件——Driver(驱动程序)、Executor(执行器)和Cluster Manager(集群管理器)——的角色和协同工作机制。通过从基础概念、工作原理、实践案例到架构选型的逐层讲解,帮助读者建立对Spark运行原理的深刻理解。
2. 基础概念 (Basic Concepts)
2.1 什么是Spark?
从本质上讲,Apache Spark是一个用于大规模数据处理的、统一的、分布式的计算引擎。它并不负责存储数据,而是专注于如何高效地计算存储在各种数据源(如HDFS、S3、关系型数据库等)中的数据。
2.2 核心组件及其职责
一个Spark应用在运行时,主要由以下三个关键组件构成,它们各司其职,共同完成计算任务。
- Driver (驱动程序):
- 角色定义:Driver是Spark应用程序的“大脑”和总指挥。它是运行应用程序main()函数并创建SparkContext的进程。
- 核心职责:
- 将用户代码解析成逻辑执行计划(DAG)。
- 向Cluster Manager申请计算资源。
- 将DAG划分为物理执行阶段(Stage),并创建任务(Task)。
- 将任务调度到Executor上执行。
- 监控所有任务的执行状态,并在任务失败时进行重试。
- Executor (执行器):
- 角色定义:Executor是运行在集群工作节点(Worker Node)上的JVM进程,是计算任务的“士兵”。
- 核心职责:
- 接收并执行Driver分配的具体任务(Task)。
- 将计算结果返回给Driver。
- 通过其内部的块管理器(Block Manager)为缓存的RDD提供内存或磁盘存储。
- Cluster Manager (集群管理器):
- 角色定义:Cluster Manager是集群的“后勤官”,是一个独立的外部服务,负责为Spark应用分配和管理物理资源(CPU、内存)。
- 核心职责:
- 接收Driver的资源申请请求。
- 在工作节点上启动Executor进程。
- 监控Executor的生命周期,并在其失败时通知Driver。
为了更清晰地理解它们的职责,请参考下表:
[此处插入核心组件职责表]
| 组件 | 核心职责 | 关键作用 |
|---|---|---|
| Driver (驱动程序) | 运行 main() 函数,创建SparkContext ,构建DAG,将任务分发给Executor。 | 应用程序的“大脑”与总指挥,负责整个作业的调度与协调。 |
| Executor (执行器) | 在工作节点上执行Driver分配的任务(Task),管理内存与磁盘中的数据。 | 计算任务的实际执行单元,是真正完成数据处理的“士兵”。 |
| Cluster Manager (集群管理器) | 负责获取和管理集群中的物理资源(CPU、内存),并将其分配给Spark应用。 | 集群的“后勤官”,为应用程序提供运行所需的计算资源。 |
2.3 Spark支持的集群管理器类型
Spark设计灵活,支持多种集群管理器,以适应不同的部署环境:
- Standalone: Spark自带的轻量级资源管理器,部署简单,适合仅运行Spark应用或用于测试的小型集群。
- Apache Hadoop YARN: Hadoop生态系统中的通用资源调度器,也是生产环境中最常用的选择,能够与其他Hadoop应用(如MapReduce)共享集群资源。
- Apache Mesos: 一个通用的数据中心资源管理器,能够调度包括Spark在内的多种分布式应用,提供更细粒度的资源共享。
- Kubernetes (K8s): 流行的容器编排系统,允许Spark应用以容器化的方式运行,非常适合云原生和微服务环境。
3. 原理机制 (Working Mechanisms)
3.1 宏观视角:Spark应用执行总览
下图描绘了Spark核心组件之间的交互关系。Driver作为中心协调者,首先与Cluster Manager通信以获取资源(Executor),然后直接与Executor通信来分发任务和收集结果。
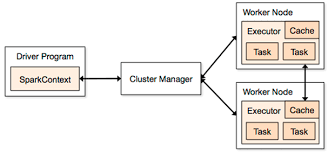
上图中的流程解释:
(a) Driver程序向Cluster Manager申请资源。
(b) Cluster Manager在Worker节点上启动Executor。
(c) Executor启动后向Driver反向注册。
(d) Driver将任务发送给Executor执行,Executor将结果返回给Driver。
3.2 详细步骤:一次完整的任务执行流程
让我们通过一个循序渐进的流程来理解Spark是如何执行一个应用的。
- 应用提交:用户通过spark-submit脚本提交打包好的应用程序(如JAR文件)。
- Driver启动:spark-submit脚本在指定的部署模式(client或cluster)下启动Driver进程。Driver进程中,应用程序的main()方法被调用,并创建SparkContext。SparkContext是与集群交互的入口。
- 资源申请:SparkContext向配置的Cluster Manager(如YARN)发出资源申请,请求启动若干个Executor。
- Executor启动与注册:Cluster Manager收到请求后,在集群中的工作节点(Worker Node)上分配资源并启动Executor进程。每个Executor启动后,会主动向Driver进行“反向注册”,以便Driver可以识别和管理它们。
- 逻辑计划构建(DAG):Driver分析用户代码中的RDD转换操作(如map, filter, join),构建一个表示计算逻辑的有向无环图(DAG)。
- 物理计划划分(Stage):当遇到一个需要进行数据混洗(Shuffle)的宽依赖操作(如reduceByKey、groupByKey)时,Driver中的DAGScheduler会将DAG切分为多个阶段(Stage)。每个Stage内部只包含窄依赖,可以以流水线方式高效执行。
- 任务分发(Task):DAGScheduler将每个Stage提交给TaskScheduler。TaskScheduler根据数据分区情况,为每个Stage生成一组任务(Task),并将这些任务(封装在TaskSet中)分发给已注册的Executor。
- 任务执行与结果返回:Executor接收到任务后,在其内部的线程池中执行。任务处理其对应的数据分区,执行结果会返回给Driver或写入外部存储。
- 应用结束:当所有任务执行完毕,Driver调用sc.stop()方法,向Cluster Manager注销应用程序并释放所有Executor资源。
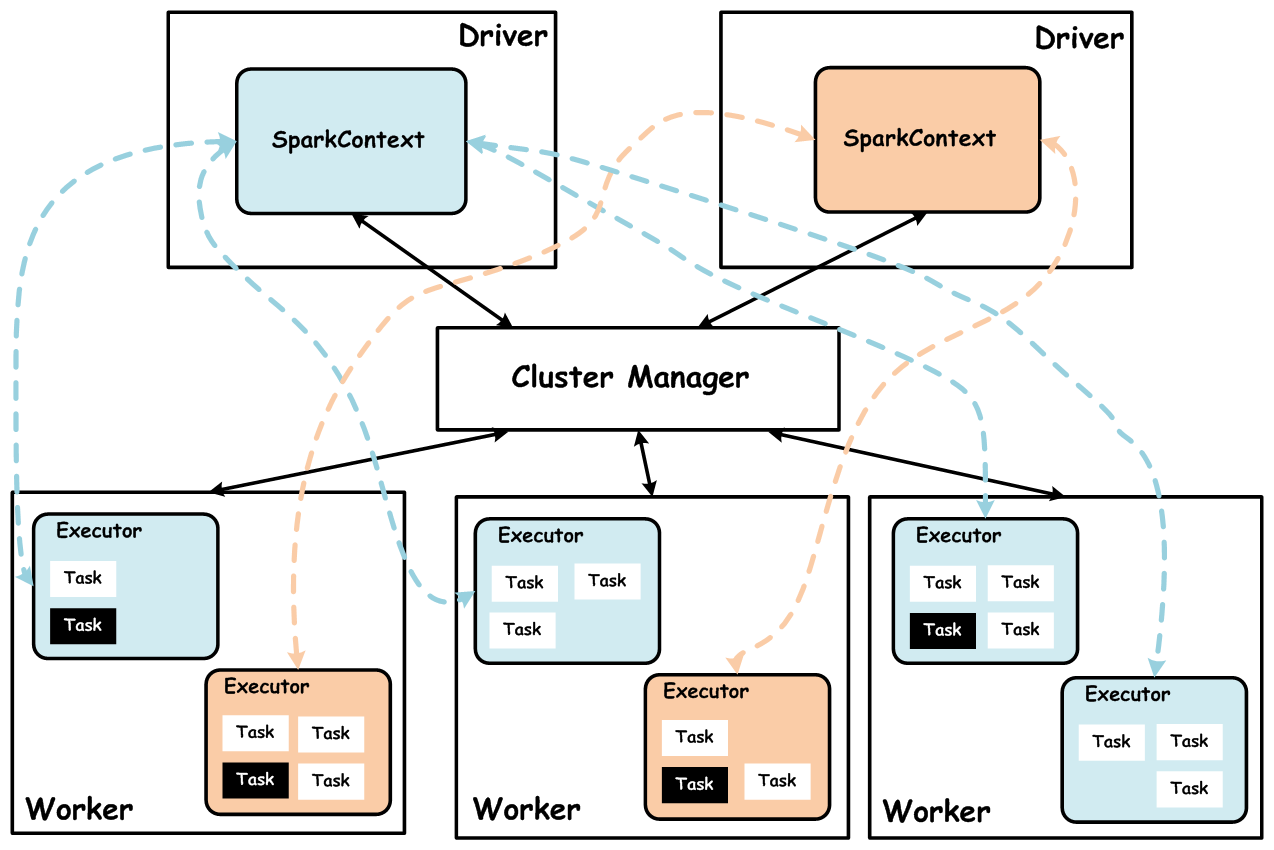
3.3 流程图解:从代码到执行
下图更直观地展示了从用户提交到任务在Executor上执行的完整流程。
4. 实践与案例 (Practice and Case Studies)
4.1 经典案例:WordCount任务执行全景解析
WordCount是学习分布式计算的“Hello World”。我们以此为例,将前面介绍的理论知识串联起来。
4.1.1 应用程序代码
假设我们有如下Scala代码来统计一个文本文件中单词的出现次数:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
// 1. 读取输入文件,创建RDD
val lines = sc.textFile("hdfs://path/to/input.txt")
// 2. 将每行文本拆分成单词
val words = lines.flatMap(_.split(" "))
// 3. 将每个单词映射为 (word, 1) 的键值对
val pairs = words.map(word => (word, 1))
// 4. 按单词聚合计数
val wordCounts = pairs.reduceByKey(_ + _)
// 5. 保存结果到HDFS
wordCounts.saveAsTextFile("hdfs://path/to/output")
sc.stop()
}
}4.1.2 DAG构建与Stage划分
当Driver分析这段代码时:
- textFile、flatMap、map都是窄依赖转换,因为每个父RDD的分区最多被一个子RDD的分区使用,它们可以在同一个Stage中流水线执行。
- reduceByKey是一个宽依赖转换,因为它需要将不同分区中相同的Key(单词)汇集到一起进行聚合,这个过程就是Shuffle。
- 因此,DAGScheduler会将这个DAG在reduceByKey处切分开,形成两个Stage:
- Stage 1:包含textFile、flatMap和map操作,负责读取数据、分词并生成(word, 1)键值对。
- Stage 2:包含reduceByKey和saveAsTextFile操作,负责对Shuffle后的数据进行聚合和保存。
4.1.3 Map阶段与Reduce阶段
- Map阶段 (Stage 1): Driver将Stage 1的任务分发给多个Executor。每个Executor并行地读取HDFS上的一部分文件块,执行flatMap和map操作,并将中间结果((word, 1)键值对)写入本地磁盘,为Shuffle做准备。
- Shuffle过程: Stage 1完成后,Executor之间会进行数据传输。每个Executor将自己生成的键值对按照Key进行哈希分区,并将属于同一分区的数据发送到负责该分区的Executor上。
- Reduce阶段 (Stage 2): 当Executor接收到所有相关的Shuffle数据后,Driver会启动Stage 2的任务。每个Executor对其本地收到的数据执行reduceByKey聚合操作,最后将结果写入HDFS。
5. 架构/系统层面 (Architectural/System Level)
5.1 集群管理器深度对比与选型
选择合适的集群管理器对于发挥Spark的性能、保障系统稳定性至关重要。
[此处插入Cluster Manager特性对比表]
| 特性/Cluster Manager | Standalone | YARN | Mesos | Kubernetes |
|---|---|---|---|---|
| 部署难度 | 最简单,Spark内置 | 中等,与Hadoop生态集成 | 中等,需要Mesos自身集群管理 | 较复杂,需要Kubernetes集群 |
| 资源管理 | Spark独有资源管理 | 通用资源管理,与Hadoop集成度高 | 通用资源管理,可调度多种工作负载 | 容器编排,提供强隔离性 |
| 通用性 | 仅支持Spark应用 | 通用,支持Hadoop生态应用 | 通用,支持多种分布式应用 | 适合容器化应用,支持多种工作负载 |
| 故障容错 | 基本容错 | 健壮,自动恢复节点故障 | 较好 | 容器化应用自动恢复、调度 |
| 适用场景 | 小型或中型Spark集群,快速测试部署 | 已有Hadoop集群,需要与其他Hadoop应用共享资源 | 需要管理除Hadoop外多种类型的分布式工作负载 | 容器化环境,微服务架构,寻求更好的隔离和弹性 |
选型建议:
- Standalone: 适用于快速原型验证、学习或小规模、专用的Spark集群。
- YARN: 当企业已经拥有成熟的Hadoop生态(HDFS、Hive等)时,YARN是无缝集成的最佳选择,尤其适合大规模生产环境。
- Mesos: 如果你的数据中心需要统一管理多种分布式框架(不仅是Hadoop生态),Mesos的细粒度资源调度能力会更有优势。
- Kubernetes: 在云原生和微服务架构下,使用Kubernetes管理Spark应用可以获得极佳的弹性、隔离性和自动化运维体验,是未来的发展趋势。
5.2 性能调优:常见问题与解决方案
5.2.1 常见配置参数
- --driver-memory: 设置Driver进程的内存大小。如果应用程序中有collect()等操作将大量数据拉回Driver,需适当调大此值。
- --executor-memory: 设置每个Executor进程可用的内存大小。这是解决OOM问题和优化性能的关键参数。
- --executor-cores: 设置每个Executor进程可用的CPU核心数,影响并行任务处理能力。
- spark.sql.shuffle.partitions: 控制Shuffle操作的并行度,即Shuffle后生成的分区数。默认值200,对于大规模数据可能需要调大以避免数据倾斜。
5.2.2 内存溢出(OOM)问题
- 现象:任务日志中出现java.lang.OutOfMemoryError。
- 原因:Executor内存不足以容纳处理的数据、数据倾斜导致某个任务负载过重、代码中不合理的缓存等。
- 解决方案:
- 增加资源:调大--executor-memory和spark.memory.fraction(执行与存储内存占比)。
- 优化代码:使用reduceByKey替代groupByKey进行预聚合;避免不必要的collect()操作。
- 增加并行度:增加repartition或调大spark.sql.shuffle.partitions,让每个任务处理更少的数据。
5.2.3 数据倾斜(Data Skew)问题
- 现象:大部分任务执行迅速,但少数几个任务执行极慢,甚至失败。通常发生在join或groupByKey等Shuffle操作之后。
- 原因:数据集中某些Key的数据量远大于其他Key,导致这些Key被分配到少数几个任务上,形成瓶颈。
- 解决方案:
- 提高Shuffle并行度:增加spark.sql.shuffle.partitions的值,分散Key到更多任务中。
- 广播小表(Broadcast Join):在join操作中,如果一个表很小,可以将其广播到所有Executor,避免大表进行Shuffle。
- 加盐(Salting):为倾斜的Key添加随机前缀,将其打散到不同的分区进行处理,最后再合并结果。
- 利用AQE:Spark 3.0+引入的自适应查询执行(Adaptive Query Execution, AQE)可以自动处理部分数据倾斜问题。
6. 总结 (Conclusion)
6.1 核心架构回顾
通过本文的分析,我们清晰地看到Spark的强大能力源于其精巧的分布式架构。Driver(指挥官) 负责全局调度与协调,Executor(士兵) 负责执行具体计算,而Cluster Manager(后勤官) 则提供稳定可靠的资源保障。三者紧密协作,构成了Spark高效、可扩展的运行基础。
6.2 关键知识点提炼
- Spark的核心优势在于其基于内存的、统一的计算模型。
- 理解RDD的依赖关系(宽依赖与窄依赖)以及DAG和Stage的划分,是掌握Spark执行原理的关键。
- Driver是整个应用的“大脑”,其性能和稳定性对整个作业至关重要。
- 在生产环境中,选择合适的集群管理器并进行针对性的性能调优,是保障应用高效、稳定运行的必要条件。

