


什么是Shuffle?
Shuffle是MapReduce框架中最核心也是最复杂的阶段,它发生在Map阶段和Reduce阶段之间。简单来说,Shuffle就是将Map任务的输出数据重新分发给相应的Reduce任务的过程。
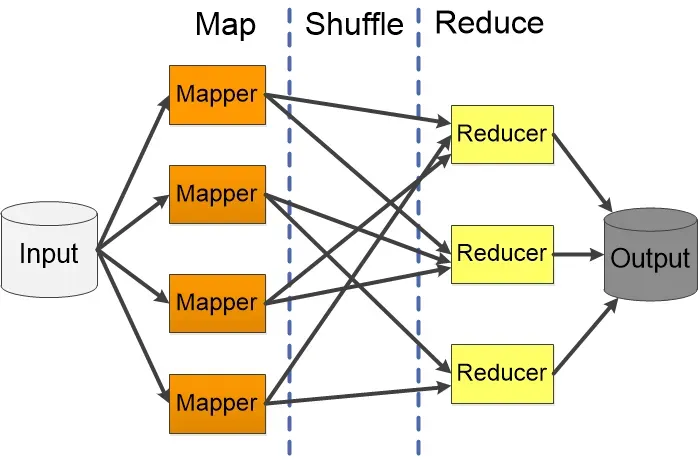
为什么需要Shuffle?
想象一个词频统计的场景:
- 多个Map任务处理不同的文档片段,每个Map都会输出(word, count)键值对
- 但同一个单词可能出现在不同的Map输出中
- 我们需要将相同key的数据汇聚到同一个Reduce任务中进行合并计算
这就是Shuffle存在的意义:数据的重新分发和聚合。
Shuffle的详细流程
1. Map端的Shuffle(Map-side Shuffle)
环形缓冲区(Circular Buffer)
- Map任务的输出首先写入内存中的环形缓冲区
- 默认大小为100MB(
mapreduce.task.io.sort.mb) - 当缓冲区使用率达到80%时触发溢写(Spill)
分区(Partition)
- 对每个键值对调用Partitioner函数确定目标Reduce任务
- 默认使用HashPartitioner:
partition = (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks - 确保相同key的数据发送到同一个Reduce任务
排序(Sort)
- 在溢写前,对缓冲区中的数据按照key进行排序
- 相同key的数据会聚集在一起,便于后续的合并操作
合并(Combine)
- 如果配置了Combiner,会在溢写前对相同key的数据进行预聚合
- Combiner本质上是一个mini-reducer,可以减少网络传输量
溢写到磁盘(Spill to Disk)
- 排序后的数据写入本地磁盘的临时文件
- 一个Map任务可能产生多个spill文件
归并(Merge)
- Map任务完成后,将所有spill文件归并成一个已排序的输出文件
- 使用多路归并排序算法,保持数据的有序性
2. Reduce端的Shuffle(Reduce-side Shuffle)
拉取数据(Fetch/Copy)
- Reduce任务主动从各个Map任务的输出中拉取属于自己的数据分区
- 通过HTTP请求获取数据,支持并行拉取
- 拉取的数据先存储在内存中,内存不足时溢写到磁盘
归并排序(Merge Sort)
- 将从不同Map任务拉取的数据进行多路归并排序
- 确保相同key的所有数据聚集在一起
- 分为内存归并和磁盘归并两个阶段
分组(Group)
- 将排序后的数据按key进行分组
- 每个key对应的所有value组成一个value集合
- 这个集合作为Reduce函数的输入
关键参数配置
Map端参数
mapreduce.task.io.sort.mb:环形缓冲区大小(默认100MB)mapreduce.map.sort.spill.percent:触发溢写的阈值(默认0.8)mapreduce.task.io.sort.factor:归并时同时打开的文件数(默认10)
Reduce端参数
mapreduce.reduce.shuffle.parallelcopies:并行拉取的线程数(默认5)mapreduce.reduce.shuffle.maxfetchfailures:拉取失败重试次数(默认10)mapreduce.reduce.shuffle.input.buffer.percent:用于存储Map输出的堆内存比例(默认0.7)
性能优化要点
1. 减少数据传输
- 合理使用Combiner:在Map端预聚合数据,减少网络传输
- 数据压缩:对Map输出进行压缩,减少磁盘I/O和网络带宽
2. 内存管理
- 调整缓冲区大小,减少溢写次数
- 合理设置Reduce端内存参数,避免频繁的磁盘I/O
3. 并行度优化
- 合理设置Map和Reduce任务数量
- 避免数据倾斜,确保各个Reduce任务负载均衡
常见面试问题
Q1:Shuffle过程中数据是如何保证不丢失的?
答案:
- Map端会将数据持久化到本地磁盘
- Reduce端拉取失败时会重试
- TaskTracker会监控任务状态,失败时重新调度
Q2:如何解决Shuffle阶段的数据倾斜问题?
答案:
- 使用自定义Partitioner,改变数据分发策略
- 对热点key进行预处理,如加随机前缀
- 调整Reduce任务数量,增加并行度
Q3:Shuffle阶段的瓶颈通常在哪里?
答案:
- 网络I/O:大量数据需要通过网络传输
- 磁盘I/O:频繁的读写操作
- CPU开销:排序和序列化/反序列化操作
Q4:为什么Shuffle阶段需要排序?
答案:
- 便于相同key的数据聚集,提高处理效率
- 支持二次排序等高级功能
- 为Reduce阶段的分组操作做准备
经典案例:单词计数中的Shuffle过程
让我们通过一个具体的单词计数例子来理解Shuffle的完整过程。
输入数据
假设我们有3个文档片段需要处理:
- 文档1: "hello world hello"
- 文档2: "world java hello"
- 文档3: "java python world"
Map阶段输出
三个Map任务分别处理这些文档:
Map1输出:
(hello, 1)
(world, 1)
(hello, 1)
Map2输出:
(world, 1)
(java, 1)
(hello, 1)
Map3输出:
(java, 1)
(python, 1)
(world, 1)
Shuffle过程详解
1. Map端Shuffle
环形缓冲区阶段
每个Map任务将输出写入环形缓冲区:
Map1缓冲区: [(hello,1), (world,1), (hello,1)]
Map2缓冲区: [(world,1), (java,1), (hello,1)]
Map3缓冲区: [(java,1), (python,1), (world,1)]
分区阶段
假设有2个Reduce任务,使用HashPartitioner分区:
hello.hashCode() % 2 = 0→ 发送给Reduce0world.hashCode() % 2 = 1→ 发送给Reduce1java.hashCode() % 2 = 0→ 发送给Reduce0python.hashCode() % 2 = 1→ 发送给Reduce1
分区结果:
Map1:
分区0: [(hello,1), (hello,1)]
分区1: [(world,1)]
Map2:
分区0: [(java,1), (hello,1)]
分区1: [(world,1)]
Map3:
分区0: [(java,1)]
分区1: [(python,1), (world,1)]
排序阶段
每个分区内按key排序:
Map1:
分区0: [(hello,1), (hello,1)] # 相同key聚集
分区1: [(world,1)]
Map2:
分区0: [(hello,1), (java,1)] # 按字母序排序
分区1: [(world,1)]
Map3:
分区0: [(java,1)]
分区1: [(python,1), (world,1)]
Combiner阶段(可选)
如果配置了Combiner,会预聚合相同key的数据:
Map1:
分区0: [(hello,2)] # (hello,1) + (hello,1) = (hello,2)
分区1: [(world,1)]
Map2:
分区0: [(hello,1), (java,1)]
分区1: [(world,1)]
Map3:
分区0: [(java,1)]
分区1: [(python,1), (world,1)]
2. Reduce端Shuffle
数据拉取阶段
Reduce0从所有Map任务拉取分区0的数据:
从Map1拉取: [(hello,2)]
从Map2拉取: [(hello,1), (java,1)]
从Map3拉取: [(java,1)]
Reduce1从所有Map任务拉取分区1的数据:
从Map1拉取: [(world,1)]
从Map2拉取: [(world,1)]
从Map3拉取: [(python,1), (world,1)]
归并排序阶段
每个Reduce任务对拉取的数据进行多路归并排序:
Reduce0归并结果:
[(hello,2), (hello,1), (java,1), (java,1)]
排序后: [(hello,2), (hello,1), (java,1), (java,1)]
Reduce1归并结果:
[(world,1), (world,1), (python,1), (world,1)]
排序后: [(python,1), (world,1), (world,1), (world,1)]
分组阶段
将相同key的数据分组,准备传递给Reduce函数:
Reduce0分组:
hello: [2, 1]
java: [1, 1]
Reduce1分组:
python: [1]
world: [1, 1, 1]
Reduce阶段处理
最终每个Reduce任务处理分组后的数据:
Reduce0输出:
(hello, 3) # 2 + 1 = 3
(java, 2) # 1 + 1 = 2
Reduce1输出:
(python, 1) # 1
(world, 3) # 1 + 1 + 1 = 3
最终结果
hello: 3
java: 2
python: 1
world: 3
关键观察点
- 数据分发: 相同的key(如hello)分散在不同Map的输出中,但通过Shuffle都汇聚到了同一个Reduce任务
- 负载均衡: 通过哈希分区,数据相对均匀地分布到不同的Reduce任务
- 排序的作用: 排序使得相同key的数据聚集在一起,便于后续的分组操作
- Combiner的效果: Map1中的两个(hello,1)被合并为(hello,2),减少了网络传输量
这个例子完整展示了Shuffle如何实现"相同key的数据汇聚到同一个Reduce任务"这一核心目标。
总结
Shuffle是MapReduce框架的核心机制,它通过分区、排序、合并、传输、归并等步骤,实现了数据的重新分发和聚合。理解Shuffle机制对于:
- 优化MapReduce作业性能
- 解决数据倾斜问题
- 设计高效的大数据处理方案
都具有重要意义。在实际应用中,需要根据具体场景调整相关参数,以达到最佳的性能表现。

