

第一部分:引言
1.1 分布式消息队列的重要性
在微服务、大数据和实时计算盛行的今天,系统间的解耦、异步通信和流量削峰成为现代技术架构的核心挑战。分布式消息队列(Message Queue, MQ)作为关键中间件,通过高效可靠的消息传递机制,完美地解决了这些难题,是构建大规模、高弹性系统的基石。
1.2 本文写作目的
本文旨在为初学者提供一个关于 Apache Kafka 的系统性入门指南,帮助你清晰地建立起对 Kafka 核心世界的认知地图。同时,也为有经验的工程师梳理和巩固 Kafka 的关键知识点,深化对底层原理的理解。
1.3 本文解决的问题
- 理解核心概念:系统掌握 Kafka 的基本术语及其相互关系。
- 掌握工作原理:深入了解 Kafka 实现高吞吐和高可用的内部机制。
- 了解应用场景:洞悉 Kafka 在真实世界中的典型用例和最佳实践。
1.4 读者对象
本文适合以下读者:
- 对分布式技术感兴趣的技术专业学生。
- 希望构建健壮后端系统的初、中级工程师。
- 需要在技术选型时评估消息队列的系统架构师。
第二部分:基础概念
2.1 消息队列(Message Queue, MQ)溯源
消息队列是一种在应用程序之间传递消息的中间件,用于解耦生产者和消费者。其核心作用包括:异步处理、流量削峰和系统解耦。随着业务复杂度的提升,分布式消息队列应运而生,它将传统MQ的功能扩展到分布式环境中,提供高可用性、高吞吐量和可伸缩性。
2.2 Kafka 的定义与定位
Apache Kafka 是一个开源的分布式流处理平台,最初由 LinkedIn 开发。它不仅仅是一个消息队列,更是一个以分布式日志为核心,集消息传递、数据存储和实时处理于一体的平台。
2.3 Kafka 核心术语解析
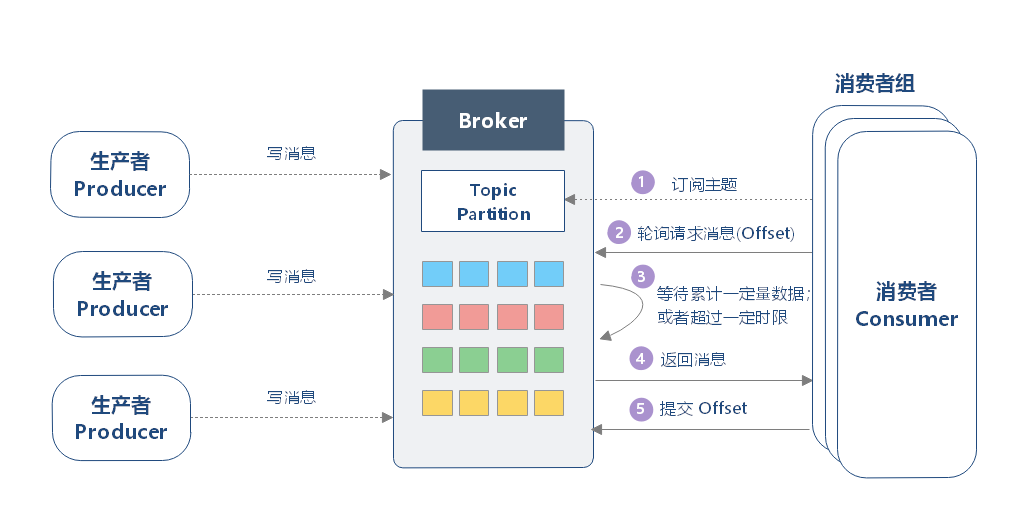
Producer (生产者): 消息的创建者和发布者,负责将消息发送到指定的 Topic。
Consumer (消费者) & Consumer Group (消费组): 消费者是消息的读取者和处理者。一个或多个消费者可以组成一个消费组,共同消费一个或多个 Topic。组内的一个 Partition 仅能被一个 Consumer 消费,以此实现负载均衡和并行处理。
Broker (代理/节点): Kafka 集群中的一台服务器,负责消息的存储、管理和转发。一个集群由多个 Broker 组成。
Topic (主题): 消息的逻辑分类,类似于数据库中的表或文件系统中的文件夹。
Partition (分区) & Offset (偏移量): 分区是 Topic 的物理划分,一个 Topic 可以包含多个分区。每个 Partition 是一个有序、不可变的消息序列,是 Kafka 实现并行处理和水平扩展的关键。Offset 是分区内每条消息的唯一、单调递增的ID,用于标识消息位置。
第三部分:原理机制
3.1 高吞吐量设计揭秘
- 顺序 I/O: Kafka 将消息顺序追加到磁盘文件中,利用了操作系统对顺序读写的高效优化,避免了磁盘随机读写的性能瓶瓶颈。
- 零拷贝 (Zero-Copy): 通过 `sendfile` 系统调用,数据直接从内核空间的页缓存(Page Cache)发送到网卡,避免了数据在内核态和用户态之间的多次拷贝,极大地提升了数据传输效率。
- 批处理与压缩: 生产者和消费者可以批量处理消息,减少网络请求次数;同时支持多种压缩算法(如 Gzip, Snappy),有效降低存储和带宽成本。
3.2 数据持久化机制:日志分段存储
每个 Partition 在物理上由一系列日志分段文件(`.log`)和对应的索引文件(`.index`, `.timeindex`)组成。消息被追加写入到活动的日志分段中,当分段文件达到一定大小或时间阈值后,会滚动生成新的活动分段。这种设计便于日志的清理和快速定位消息。
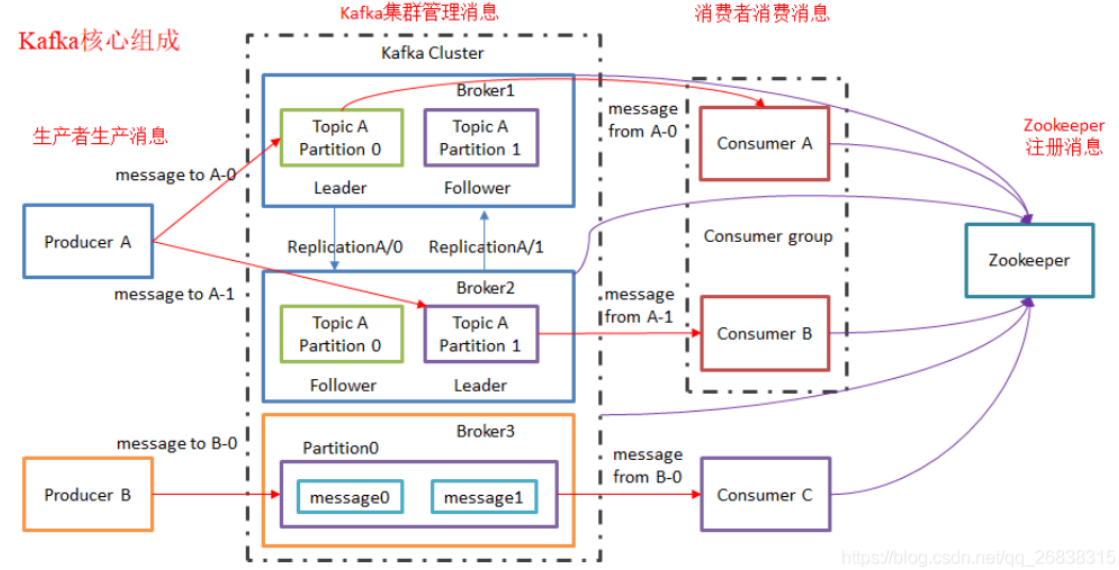
3.3 副本 (Replication) 机制:高可用的保障
为了高可用和数据冗余,每个 Partition 都会有多个副本,分布在不同的 Broker 上。
- Leader 与 Follower 角色: 每个 Partition 有且仅有一个 Leader 副本,负责处理所有读写请求。其他 Follower 副本被动地从 Leader 处拉取数据,保持同步。
In-Sync Replicas (ISR): 一个动态维护的同步副本集合,包含 Leader 以及所有与 Leader 保持“同步”状态的 Follower。当 Leader 故障时,只有 ISR 内的 Follower 才有资格被选举为新 Leader。一条消息只有被 ISR 中所有副本都确认后,才被视为“已提交”。
3.4 主流消息队列对比分析
为了更好地进行技术选型,我们将 Kafka 与 RabbitMQ 和 RocketMQ 进行对比。它们各有千秋,适用于不同的业务场景。
- 要高吞吐+可回放的事件流 → 选 Kafka(配合 Flink/Spark 很香)。
- 要业务解耦+低延迟+路由灵活 → 选 RabbitMQ(AMQP 生态、管理面优秀)。
- 要原生事务消息/延时消息 → 选 RocketMQ(电商类场景友好)。
第四部分:实践与案例
4.1 典型应用场景
- 日志聚合: 作为日志收集中心,统一接收来自不同系统的日志数据,并提供给 ELK 等系统进行分析和展示。
- 实时数据处理与流计算: 作为数据管道,无缝对接 Flink、Spark Streaming 等流处理框架,构建实时监控、推荐系统和风控引擎。
- 事件溯源 (Event Sourcing): 利用 Kafka 不可变的日志特性,存储系统中所有状态变更的事件序列,为系统提供可审计、可回溯的能力。
- 系统解耦与异步通信: 在微服务架构中充当消息总线,解耦服务间的依赖,允许服务独立演进和异步执行任务。
4.2 Kafka 最佳实践
- Topic 命名规范: 建议采用 `业务.数据类型.行为` 的结构,如 `trade.order.created`,以保证清晰可读。
- 分区数选择: 分区数应综合考虑集群规模、吞吐量需求和消费者并行度。一个常见的起点是将其设置为 Broker 数量的整数倍。
- 生产者 `ack` 配置:
- `ack=0`: 性能最高,但可能丢数据。
- `ack=1`: Leader 确认即可,性能与可靠性均衡。
- `ack=all (-1)`: 所有 ISR 副本确认,可靠性最高,但性能最低。
4.3 常见错误与解决方案
消息丢失问题分析: 主要从生产者(`ack` 配置不当)、Broker(副本数不足、`min.insync.replicas` 设置过低)和消费者(先提交 Offset 再处理消息)三个环节排查。
重复消费问题分析: 通常发生在消费者处理完消息但提交 Offset 前宕机的情况。解决方案是保证消费逻辑的幂等性,即多次执行同一操作产生相同的结果。
第五部分:架构/系统层面
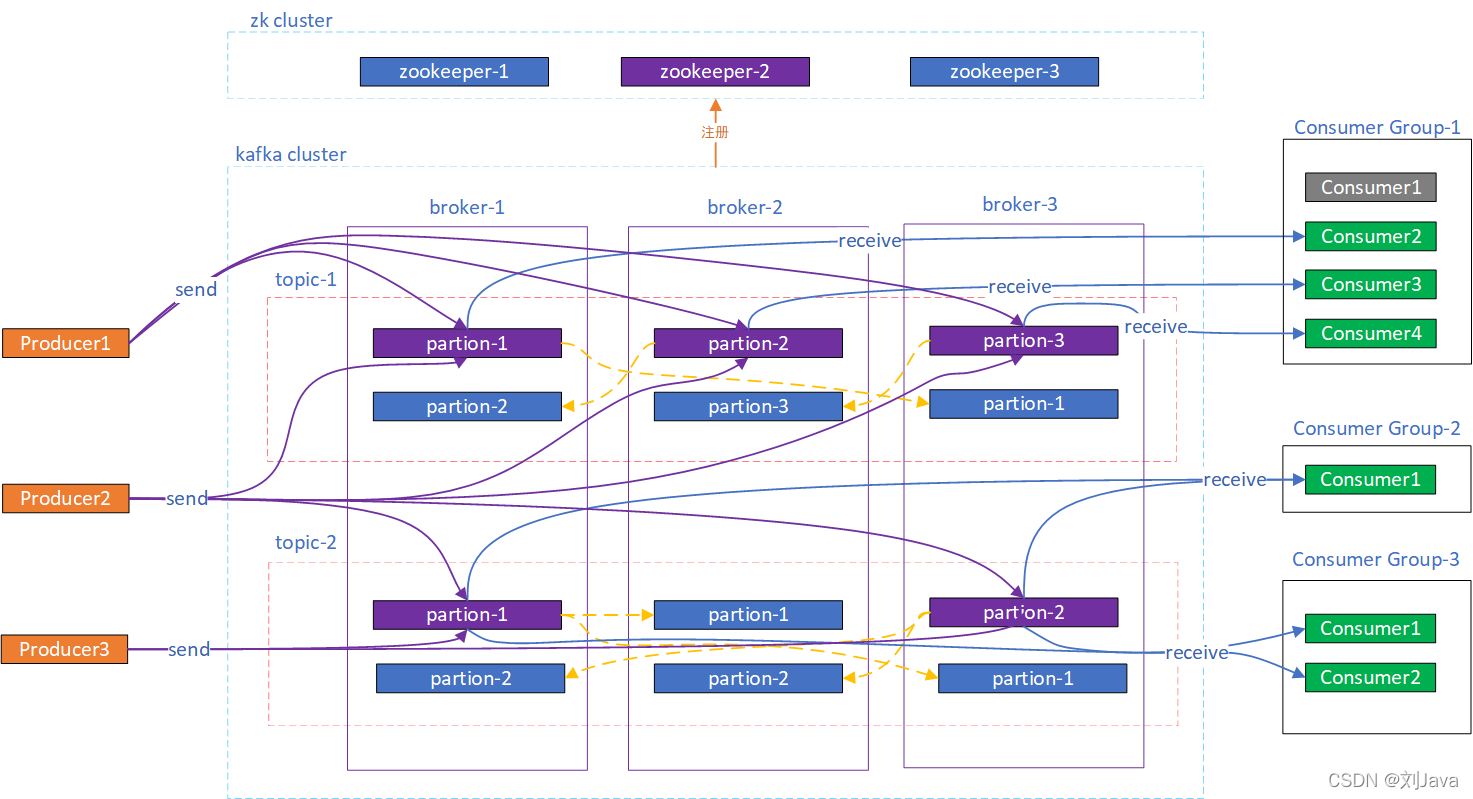
5.1 Kafka 集群完整架构
一个典型的 Kafka 集群由多个 Broker 组成,生产者和消费者通过网络与集群交互。Broker 之间通过内部协议进行数据复制和故障转移,而集群的元数据管理和协调工作则由 ZooKeeper 或 KRaft 负责。
5.2 组件协同工作流程
整个系统的工作流程精密而高效:Producers 将消息推送到 Broker 的 Leader Partition;Broker 上的 Follower Partitions 从 Leader 处异步复制数据;Consumers 以消费组的形式,从其订阅的 Topic 的 Leader Partitions 拉取消息。这个过程由协调服务统一管理。
5.3 Zookeeper / KRaft 的角色变迁
- Zookeeper (旧架构): 作为独立的协调服务,负责 Broker 注册、Topic 配置管理、Leader 选举和消费者组 rebalance 等元数据管理工作。它虽然强大,但也增加了系统的运维复杂性。
- KRaft (新架构): Kafka 3.0+ 引入,使用内建的 Raft 协议替代 ZooKeeper,将元数据管理整合到 Kafka Broker 内部。这简化了部署架构,消除了对外部系统的依赖,提升了系统的稳定性和扩展性。
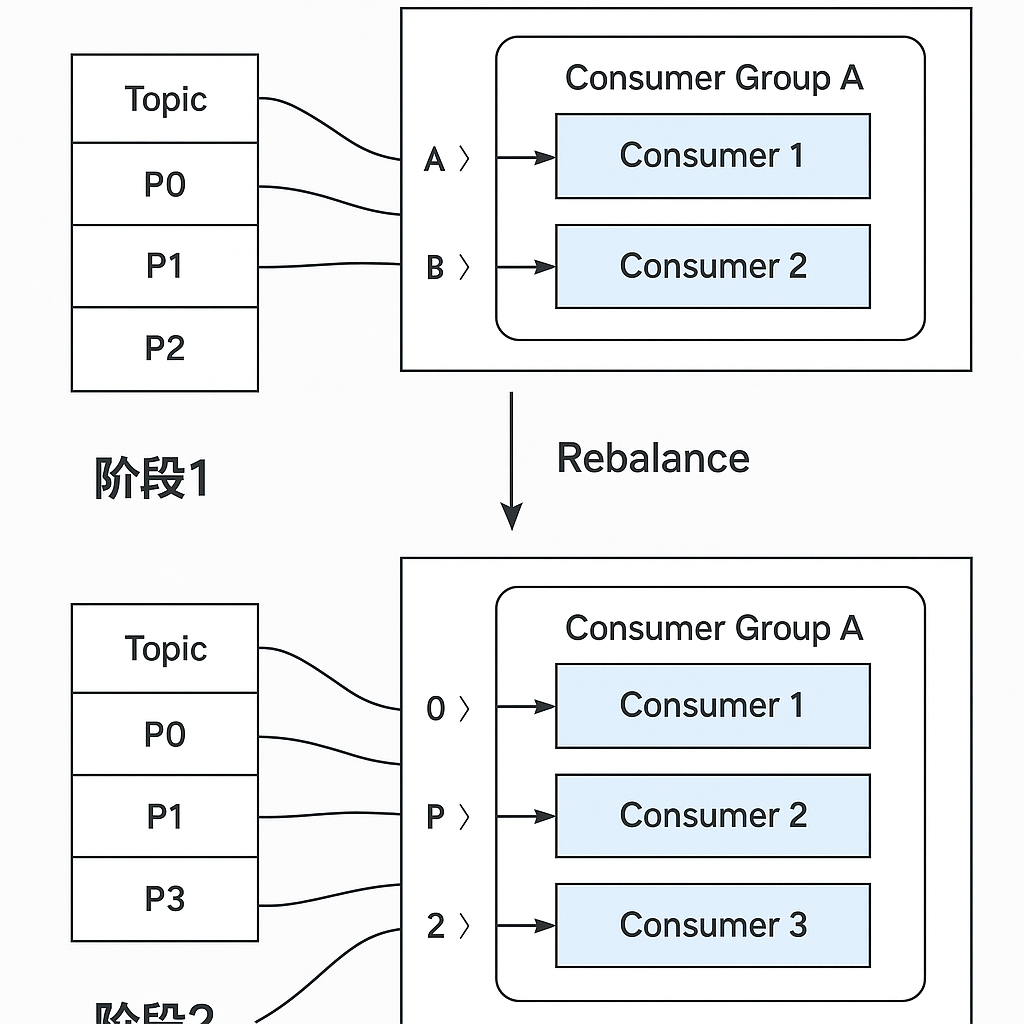
5.4 消费者组 Rebalance 机制
当消费组内的消费者数量发生变化(如新增、宕机或主动退出)时,或者订阅的 Topic 分区数发生变化时,会触发 Rebalance(再均衡)机制。Rebalance 的目的是将分区重新均匀地分配给组内所有存活的消费者,以保证所有分区都被消费且负载均衡。
第六部分:总结
6.1 核心要点回顾
本文系统地介绍了 Kafka 作为一个分布式流平台的定位及其核心组件。我们深入探讨了其实现高吞吐和高可用的两大支柱:分区机制(实现扩展性)和副本机制(保障高可用性)。
6.2 Kafka 的核心优势
- 高吞吐量: 得益于顺序 I/O 和零拷贝技术。
- 高可用性: 分布式副本和 ISR 机制确保数据不丢失。
- 高可扩展性: 通过增加 Broker 和分区方便地进行水平扩展。
- 持久化与可回溯: 消息持久化存储,支持重放历史数据。
6.3 Kafka 的挑战与权衡
尽管 Kafka 功能强大,但也存在挑战。例如,其运维复杂性较高,需要专业的知识进行调优和故障排查。此外,Kafka 仅保证单个 Partition 内的消息有序,实现全局有序则会牺牲并行处理能力。
尽管如此,Kafka 凭借其卓越的性能和强大的生态系统,已成为构建现代数据密集型应用的事实标准。希望本文能为你开启 Kafka 的学习之旅提供坚实的基础。v

