


第一章: 架构概览 (Overview)
在讨论具体组件之前,我们需要先建立一个宏观的集群模型。Kafka 的架构本质上是一个基于磁盘的分布式提交日志服务(Distributed Commit Log Service)。
1.1 核心角色定义
Kafka 集群由以下几个核心角色组成,它们共同构建了一个高吞吐的流平台:
| 组件角色 | 英文名称 | 核心定义与职责 |
|---|---|---|
| 消息代理 | Broker | Kafka 的服务器节点。一个集群包含多个 Broker。它的核心职责是接收消息、持久化存入磁盘、并响应消费者的拉取请求。 |
| 生产者 | Producer | 数据的发送端。负责将消息发送到特定的 Topic 和 Partition。Producer 决定了消息的“路由”策略(是轮询发,还是按 Key Hash 发)。 |
| 消费者 | Consumer | 数据的接收端。采用 Pull (拉) 模式从 Broker 获取数据。Consumer 自己维护消费进度 (Offset),这使得 Kafka 可以同时支持实时流计算和离线批处理。 |
| 协调者 | Zookeeper / Controller | 集群的“大脑”。负责管理元数据(如 Topic 有几个分区,谁是 Leader)、检测 Broker 的健康状态(心跳机制)以及触发重平衡 (Rebalance)。 |
Kafka 核心角色清单
协调者 (Zookeeper / Controller)
- 集群的“大脑”。负责管理元数据(如 Topic 有几个分区,谁是 Leader)、检测 Broker 的健康状态(心跳机制)以及触发重平衡 (Rebalance)。
消费者 (Consumer)
- 数据的接收端。采用 Pull (拉) 模式从 Broker 获取数据。Consumer 自己维护消费进度 (Offset),这使得 Kafka 可以同时支持实时流计算和离线批处理。
生产者 (Producer)
- 数据的发送端。负责将消息发送到特定的 Topic 和 Partition。Producer 决定了消息的“路由”策略(是轮询发,还是按 Key Hash 发)。
消息代理 (Broker)
- Kafka 的服务器节点。一个集群包含多个 Broker。它的核心职责是接收消息、持久化存入磁盘、并响应消费者的拉取请求。
1.2 架构拓扑图
为了直观展示各组件关系,请参考下方的架构拓扑:
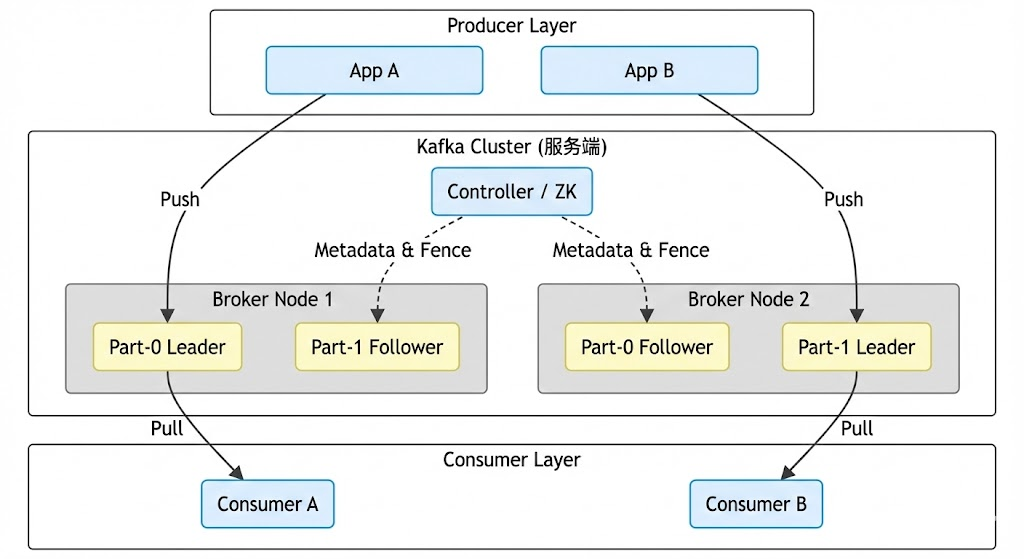
第二章: 逻辑模型 (Logical Architecture)
Kafka 的逻辑设计是其能够支撑大规模并发的关键。它引入了 Topic 和 Partition 的概念,解决了单机存储和吞吐的瓶颈。
2.1 Topic (主题)
Topic 是一个逻辑概念,它是消息的分类容器。在物理层面上,你找不到一个叫 "Topic" 的文件,你只能找到 Partition。
- 类比:数据库中的 Table(表)。
- 作用:隔离不同的业务数据流(例如:
order_logs和user_clicks是两个不同的 Topic)。
2.2 Partition (分区) —— 扩展性的基石
如果 Kafka 只有一个 Topic 且不可拆分,那它最多只能利用一台机器的磁盘 IO。为了水平扩展,Kafka 引入了 Partition。
- 分片机制 (Sharding):一个 Topic 被切割成多个 Partition(分区),分散存储在集群的各个 Broker 上。
- 并发原理:Partition 是 Kafka 并行处理的最小单位。
- 写并发:Producer 可以同时向 P0, P1, P2 发送数据。
- 读并发:一个 Consumer Group 内,不同的 Consumer 实例可以同时消费不同的 Partition。
- 有序性约束:Kafka 仅保证 Partition 内部消息有序,不保证 Topic 全局有序。
2.3 Offset (位移)
每条消息在 Partition 中都有一个唯一的序号,叫 Offset。
- 绝对位置:Offset 是一个单调递增的 Long 类型整数(64位)。
- 不可变性:一旦消息写入并分配了 Offset,该消息的内容和顺序就不可改变。
第三章: 物理存储架构 (Physical Architecture)
这是本文的重点。作为 DE,我们需要深入到磁盘目录,看看 Kafka 到底是怎么存数据的。这种存储结构的设计直接决定了 Kafka 的读写性能。
3.1 目录结构层级
假设我们在 server.properties 中配置了 log.dirs=/data/kafka-logs,且创建了一个名为 user-events 的 Topic,有 2 个分区。磁盘上的目录结构如下:
Plaintext
/data/kafka-logs/
├── user-events-0/ <-- 分区 0 的物理目录
│ ├── 00000000000000000000.log <-- 真实数据文件 (Segment 1)
│ ├── 00000000000000000000.index <-- 位移索引文件
│ ├── 00000000000000000000.timeindex <-- 时间索引文件
│ ├── 00000000000000000000.snapshot <-- 状态快照
│ ├── leader-epoch-checkpoint <-- Leader 纪元检查点
├── user-events-1/ <-- 分区 1 的物理目录
│ ├── ... (同上)
├── cleaner-offset-checkpoint <-- 日志清理检查点
└── recovery-point-offset-checkpoint <-- 数据恢复检查点
3.2 Log Segment (日志段) 的设计哲学
Kafka 为什么不把一个 Partition 存成一个无限大的文件?
如果只有一个大文件,要想删除 7 天前的数据(TTL),需要在文件头部进行复杂的“截断”操作,这在文件系统中极其低效且危险。
Kafka 采用了 分段 (Segmentation) 策略:
- 切分规则:Partition 被物理切分成多个 Segment。
- 滚动条件:当当前 Segment 写满了(默认 1GB,参数
log.segment.bytes)或者时间到了(默认 7天,参数log.roll.hours),就会关闭当前文件,创建一个新的 Segment。 - 命名规则:Segment 文件的名字是该段中第一条消息的 Offset(左补零至 20 位)。例如
00000000000000003680.log表示该文件从 Offset 3680 开始存储。
3.3 深入解析索引文件 (.index & .timeindex)
Kafka 的查询速度极快,得益于它的索引设计。很多同学以为 Kafka 会为每一条消息建索引,其实不然。
3.3.1 稀疏索引 (Sparse Index)
为了节省内存,Kafka 采用稀疏索引。
- 机制:不是每条消息都写索引,而是每隔一定字节数(默认 4KB,参数
log.index.interval.bytes)才在.index文件中追加一条索引记录。 - 优势:索引文件非常小,可以完全加载到操作系统的内存(PageCache)中,避免磁盘随机读。
3.3.2 .index 文件格式详解
.index 文件中的每一条记录固定占用 8 字节:
- Relative Offset (4 Bytes):相对位移。
- 为什么不用 8 字节的绝对 Offset? 为了省空间。这里存的是
Absolute Offset - Base Offset。比如文件名是 3680,这条消息是 3685,这里只存 5。
- 为什么不用 8 字节的绝对 Offset? 为了省空间。这里存的是
- Position (4 Bytes):物理位置。
- 这条消息在对应
.log文件中的物理字节位置。
- 这条消息在对应
3.3.3 [图解] 查找算法:如何找到 Offset = 3687 的消息?
假设我们有以下 Segment:
- Segment A:
000000.log - Segment B:
003000.log(Base Offset = 3000)
查找步骤:
- 二分定位 Segment:Kafka 在内存中维护了一个跳表(SkipList),快速判断 3687 > 3000,定位到 Segment B。
- 二分查找 Index:加载 003000.index,通过二分查找找到 <= 3687 的最大索引项。假设找到索引项:[RelOffset=680, Position=5120]。计算绝对 Offset = 3000 + 680 = 3680。
- 顺序扫描 Log:打开 003000.log 文件。利用 seek() 也就是文件指针直接跳到物理位置 5120。从 5120 开始,顺序向后读取消息(Deserialize),直到读到 Offset 为 3687 的那条。
小万总结:这种“二分查找 + 顺序扫描”的组合,将磁盘 IO 降到了最低。
第四章: 副本架构与高可用 (Replication & HA)
Kafka 作为一个分布式系统,必须容忍硬件故障。副本(Replica)机制是其高可用的核心。
4.1 Leader 与 Follower
每个 Partition 都有多个副本,副本之间通过 Leader-Follower 模式协作。
- Leader:
- 读写权:默认情况下,所有的生产者写入请求、消费者读取请求,全部由 Leader 处理。
- 职责:负责维护 ISR 列表,负责将数据写入本地 Log。
- Follower:
- 备份权:不处理客户端请求(除非开启了 Follower Fetching)。
- 职责:唯一的任务就是向 Leader 发送 Fetch Request,拉取数据并写入本地 Log,极力保持与 Leader 的同步。
4.2 ISR (In-Sync Replicas) 动态集合
Kafka 并没有简单地规定“半数以上节点存活才可用”(Quorum),而是设计了 ISR 机制。
- AR (Assigned Replicas):所有配置的副本集合。
AR = ISR + OSR。 - ISR (In-Sync Replicas):当前“活着”且“跟得上”Leader 的副本集合。
- OSR (Out-of-Sync Replicas):滞后的副本集合。
- 判定标准:参数
replica.lag.time.max.ms(默认 30s)。如果 Follower 在 30 秒内没有向 Leader 发送 Fetch 请求,或者虽然发了但 30 秒都没追上 Leader 的最新水位,就会被 Leader 踢出 ISR。
4.3 HW 与 LEO:数据一致性的边界
这是面试中最硬核的部分,决定了数据是否会丢失,是否会“脏读”。
| 术语 | 全称 | 解释 | 作用 |
| LEO | Log End Offset | 日志末端位移。记录了该副本当前写入的下一条消息的 Offset。 | 标识当前副本到底写了多少数据。Leader 和 Follower 都有自己的 LEO。 |
| HW | High Watermark | 高水位。取值为 ISR 集合中最小的 LEO。 | 消费者的可见边界。消费者只能拉取到 HW 之前的数据。 |
为什么要有 HW?
为了保证Leader 切换时的数据一致性。
假设 Leader 写入了 Offset 100,但 Follower 只同步到了 90。此时 HW=90。消费者只能读到 90。
如果 Leader 挂了,Follower 变成新 Leader,它的 LEO 是 90。
如果之前允许消费者读到了 100,那新 Leader 上线后,消费者发现 Offset 91-100 凭空消失了,这在金融场景下是不可接受的。HW 机制强制规避了这个问题。
第五章: IO 模型与高性能原理 (Kernel & IO)
Kafka 能在普通机械硬盘上跑出单机几百 MB/s 的吞吐量,主要依赖两大 OS 层面的黑科技。
5.1 磁盘顺序写 (Sequential Write)
我们在架构设计上坚决避免随机写。
- 随机 I/O:磁头频繁寻道,速度极慢(几十 KB/s - 几 MB/s)。
- 顺序 I/O:磁头几乎不动,数据在盘片上连续写入,速度极快(几百 MB/s),甚至超过内存的随机写速度。
- Kafka 实现:所有的消息都是 Append Only(追加写)到
.log文件末尾。Kafka 不支持修改已写入的消息,也不支持从文件中间插入数据。
5.2 零拷贝 (Zero Copy) 技术
这是 Java 高性能网络编程的精髓。
当消费者拉取数据时,数据需要从磁盘发送到网卡。
传统模式 (4次拷贝,4次上下文切换):
- Disk -> Kernel Buffer (DMA)
- Kernel -> User Buffer (CPU Copy)
- User -> Socket Buffer (CPU Copy)
- Socket -> NIC (DMA)痛点:数据在内核态和用户态之间反复横跳,CPU 忙于搬运数据。
Kafka Sendfile 模式 (2次拷贝,2次上下文切换):
Kafka 调用 Linux 的 sendfile 系统调用(Java 中对应 FileChannel.transferTo)。
- Disk -> PageCache (Kernel) (DMA)
- PageCache -> NIC (网卡) (SG-DMA 描述符拷贝)优势:数据根本不进入 JVM 内存!CPU 负载极低。
第六章: 小万的 Discord 社区实战案例集
理论结合实战,以下选自 「小万的 DATA 成长营地」 真实案例。
案例 1:Topic 副本与机架感知 (Rack Awareness)
用户:@Cloud_Architect
场景:
* "小万,我们在 AWS 上部署 Kafka,有 3 个可用区 (AZ)。但是我看所有的 Leader 经常集中在同一个 AZ 里,跨区流量费很贵,怎么解?"
小万解析:
* 这是 Kafka 的物理架构感知问题。
默认情况下,Kafka 分配副本是不看物理位置的。你需要配置 broker.rack 参数。
解决:
- 在 Broker 配置中设置
broker.rack=us-east-1a(根据实际 AZ 填写)。创建 Topic 时,Kafka 会自动尝试将 Partition 的 3 个副本分散到不同的 rack 上。这样不仅保证了一个机房挂了数据不丢,配合 Follower Fetching(从本地 Follower 读数据),还能节省跨区流量费。
案例 2:Log Retention 导致的磁盘“满而不清”
用户:XXX
场景:
* "生产环境磁盘报警 90%,我检查了 log.retention.hours=24,理论上昨天的日志应该删了,但 du -sh 看到文件还在。"
小万解析:
* 很多人误解了 Retention 的触发时机。Kafka 删除数据的最小单位是 Segment。
如果一个 Segment 只要还有一条消息没过期,整个 Segment 都不会删。
更重要的是,如果一个 Segment 正在被写入(Active Segment),它永远不会被删,即使里面的数据已经过期 100 年了。
解决:
* 检查 log.segment.bytes。该用户因为流量极低,默认 1GB 的 Segment 写了一个月都没写满,导致文件一直处于 Active 状态,无法轮转(Roll),也就无法被清理。建议调小至 100MB。
案例 3:Controller 脑裂与元数据同步
用户:xxx
场景:
- "旧版 Kafka (2.4),ZK 网络抖动了一下,结果整个集群几分钟不可用,日志里全是 NotLeaderForPartitionException。"
小万解析: - 这是旧版架构的通病。ZK 抖动导致 Controller 发生切换。新 Controller 上位后,需要从 ZK 读取几十万个 Partition 的元数据,然后一条条推送给所有 Broker。这个过程非常慢。
解决:
- 短期优化 ZK 参数。长期建议升级到 Kafka 3.x 使用 KRaft 模式。KRaft 将元数据存储在内部 Topic 中,Controller 切换只需读取内存快照,毫秒级恢复。

