

开篇:当你的数据库开始“发福”
话说,咱们虚构一个快速发展的社交应用“ConnectSphere”。一开始,用户表设计在MySQL里,岁月静好。但随着业务迭代,产品经理一天一个想法,用户属性字段从10个激增到500个!什么兴趣爱好、教育背景、工作经历、常访问的页面、点赞过的商品... 好家伙,一个比一个能加。
很快,DBA小哥的脑阔开始疼了,因为他发现:
- 存储浪费: 大部分用户只填了十几个字段,导致数据库表里充满了大量的
NULL值,硬盘空间像漏了气的气球一样瘪下去。 - 性能瓶颈: 想统计所有用户的“城市”和“年龄”,数据库却傻乎乎地把每个用户的500个字段全读出来,再丢掉498个,这I/O开销简直是在“烧钱”。
- 扩展性噩梦: 每次加个新属性,都得提心吊胆地
ALTER TABLE。在几十亿行数据的大表上搞这个,跟走钢丝没啥区别。
DBA小哥仰天长啸:“难道就没有一种更适合这种‘宽表’、‘稀疏’数据的数据库吗?”
答案是肯定的!今天,咱们就来认识一下大数据领域的“瑞士军刀”—— HBase。它通过一种名为“列式存储”的魔法,完美解决了上述难题。本文将带你揭开HBase的神秘面纱,理解其核心数据模型,并掌握其性能的命脉——表设计。
HBase的核心世界观:一个巨大、有序、多维的字典
忘掉传统数据库的条条框框,让我们用一个更简单的模型来理解HBase。你可以把它想象成一个:
巨大无比、自动排序、而且还是多维度的字典(Map)。
这个“字典”有几个关键组件,咱们一层层把它扒开。
HBase的数据模型
假设我们还是“ConnectSphere”的用户表,逻辑上它可能长这样:
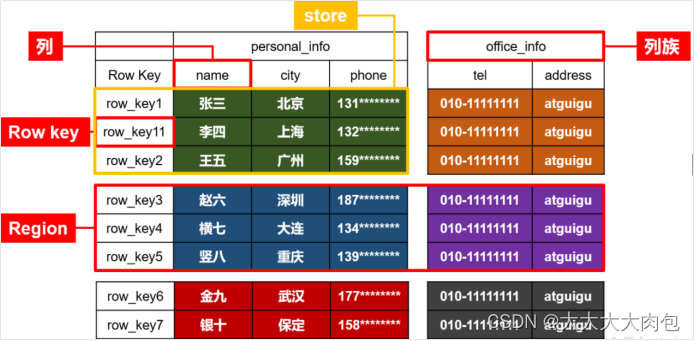
上图右侧完美地展示了HBase的真实面貌,它由以下几个核心元素构成:
- RowKey (行键): 这是字典的“键”,也是HBase世界里唯一的主键索引。它是一个字节数组(
byte[]),所有数据都严格按照RowKey的字典顺序进行排序。 - Column Family (列族): 这是HBase“多维”特性的关键。你可以把它想象成一个“文件夹”。比如,用户的基本信息放进
info文件夹,偏好设置放进prefs文件夹。重点:列族必须在建表时预先定义,而且不宜过多(通常2-3个足矣)。 - Column Qualifier (列限定符): 文件夹里的“文件”。比如
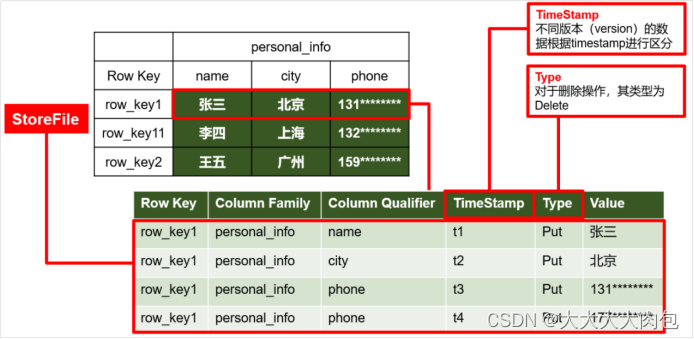
info文件夹里有name、age文件。它非常灵活,无需预定义,可以随时动态增删。 - Cell (单元格) & Timestamp (时间戳): 每个“文件”的内容就是单元格的值(Value)。并且,HBase天生自带“版本历史记录”(Timestamp),每次修改都会生成一个新版本,并保留旧版本。查询时默认返回最新的那一个。
# 例如,创建一个名为'users'的表,包含'info'和'prefs'两个列族
create 'users', 'info', 'prefs'知识要点:核心坐标
在HBase中,一个值(Value)由 {RowKey, Column Family, Column Qualifier, Timestamp} 这四个坐标唯一确定。
列式存储的魔法:为什么HBase这么快?
理解了数据模型,我们再来看看HBase高性能的秘密武器——列式存储(更准确地说是“面向列族的存储”)。
经典类比:学生档案室
行式存储 (MySQL): 像一个学生档案柜,每个抽屉是一个学生(一行),里面装着该学生的所有科目成绩单(所有列)。要统计全校的数学平均分,你得打开每个学生的抽屉,找出数学成绩单。学生一多,你就疯了。
列式存储 (HBase): 像一个科目档案柜,每个抽屉是一个科目(一个列族)。“数学”抽屉里装着所有学生的数学成绩单,“语文”抽屉里装着所有学生的语文成绩单。要统计数学平均分,你只需要打开“数学”这一个抽屉就行!I/O效率高到飞起!
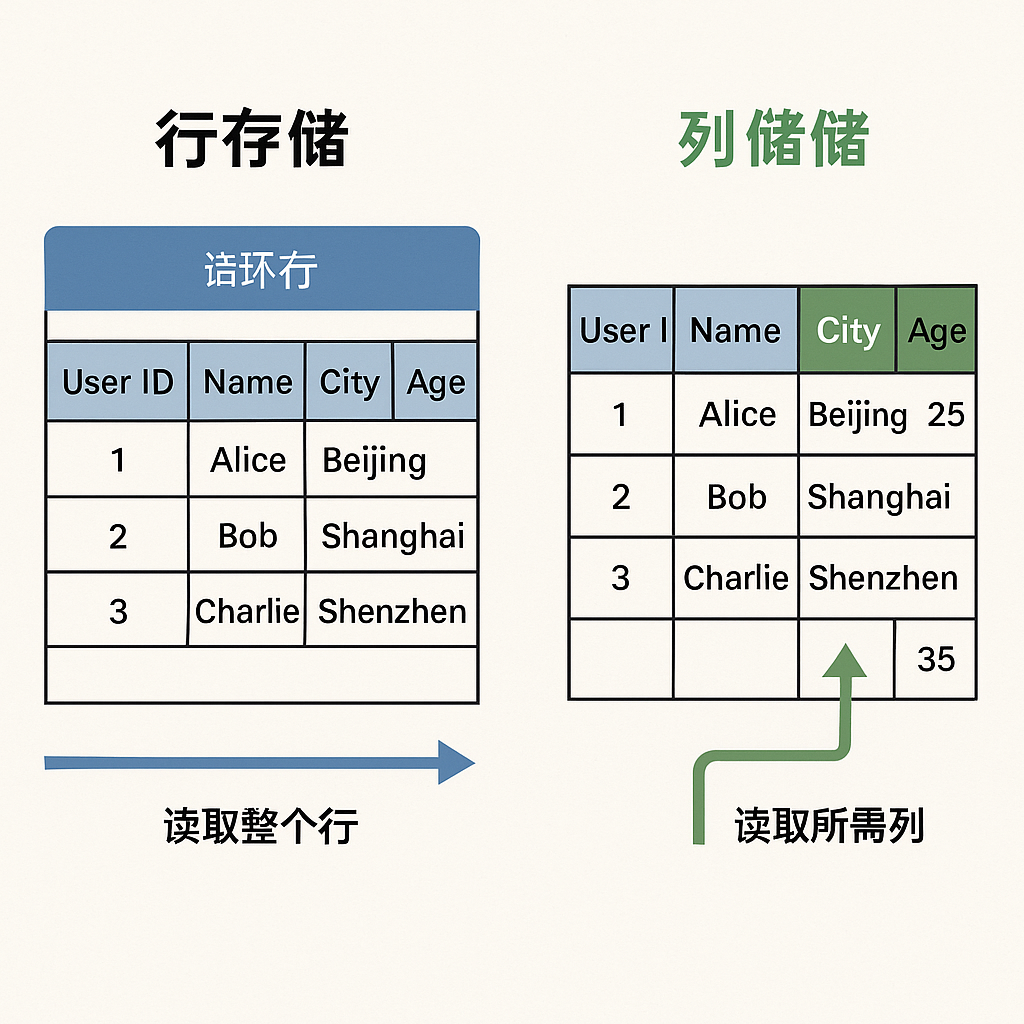
上图非常直观地展示了差异。行存把一行数据连续存放在一起,而列存把一列数据连续存放在一起。这种存储方式在HBase中体现为面向列族(Column Family)的存储。如下图所示,对于同一行数据,分属不同列族(如 info 和 prefs)的列会存储在不同的物理文件中。这种分离确保了当查询只涉及info列族时,硬盘只需读取与info相关的文件,完全避免了对prefs列族数据的I/O访问。
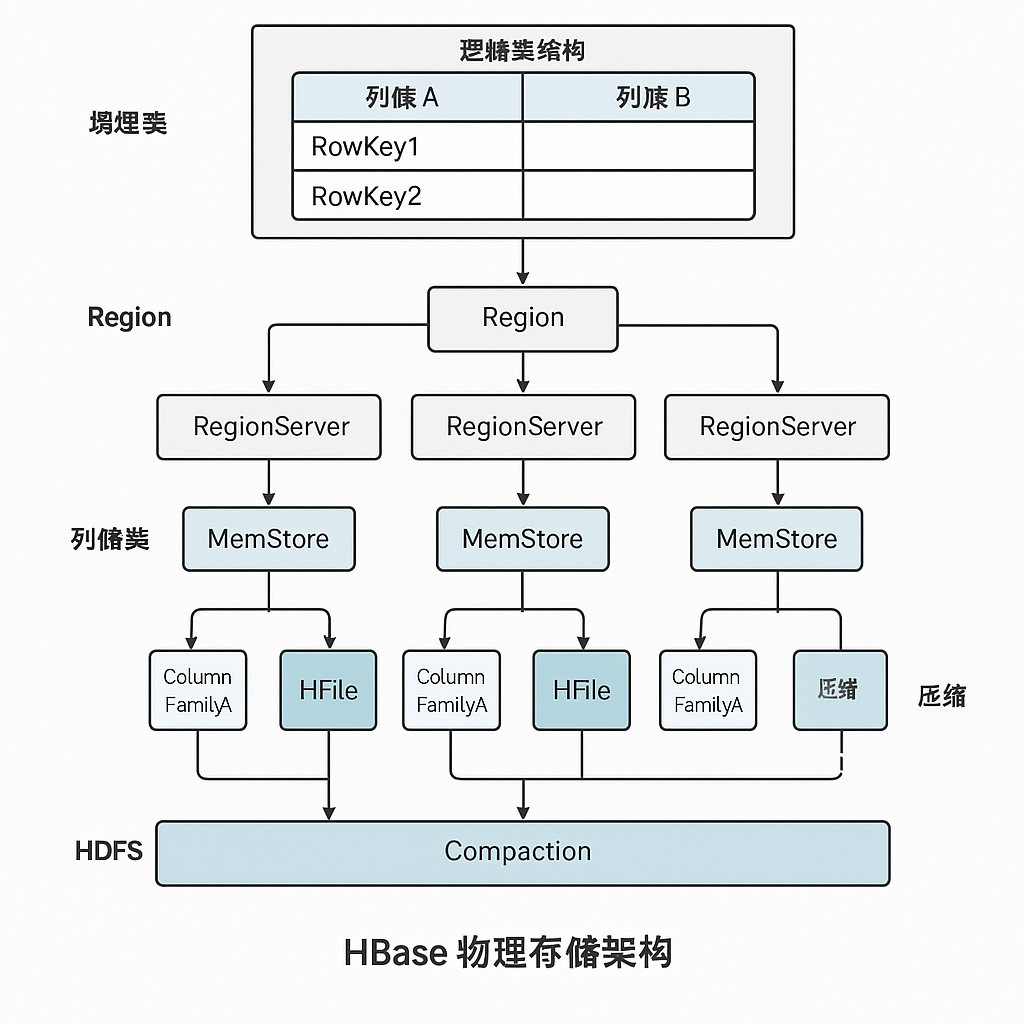
这种面向列族的存储方式带来了两大核心优势:
- I/O高效: 当你只需要查询几个特定列时,HBase只需读取包含这些列的列族文件,而无需扫描整行数据,大大减少了磁盘I/O。
- 压缩更优: 同一个列族里的数据类型和特征通常很相似,因此可以采用更高效的压缩算法,极大地节省存储空间。例如,一个只包含整数的列,其压缩效率远高于一个既包含整数、又包含长字符串和日期等混合类型的行。
表设计的艺术:RowKey定乾坤
如果说列族是HBase的骨架,那么RowKey就是HBase的灵魂。毫不夸张地说,RowKey的设计直接决定了HBase集群的生死。
热点问题:高速公路只开一个收费口
由于HBase的数据是按RowKey字典序排列的,如果你设计的RowKey是单调递增的(比如用时间戳、自增ID),那么所有新的写入请求都会像发疯一样涌向集群的同一个Region(数据分区),而其他Region则闲得发慌。
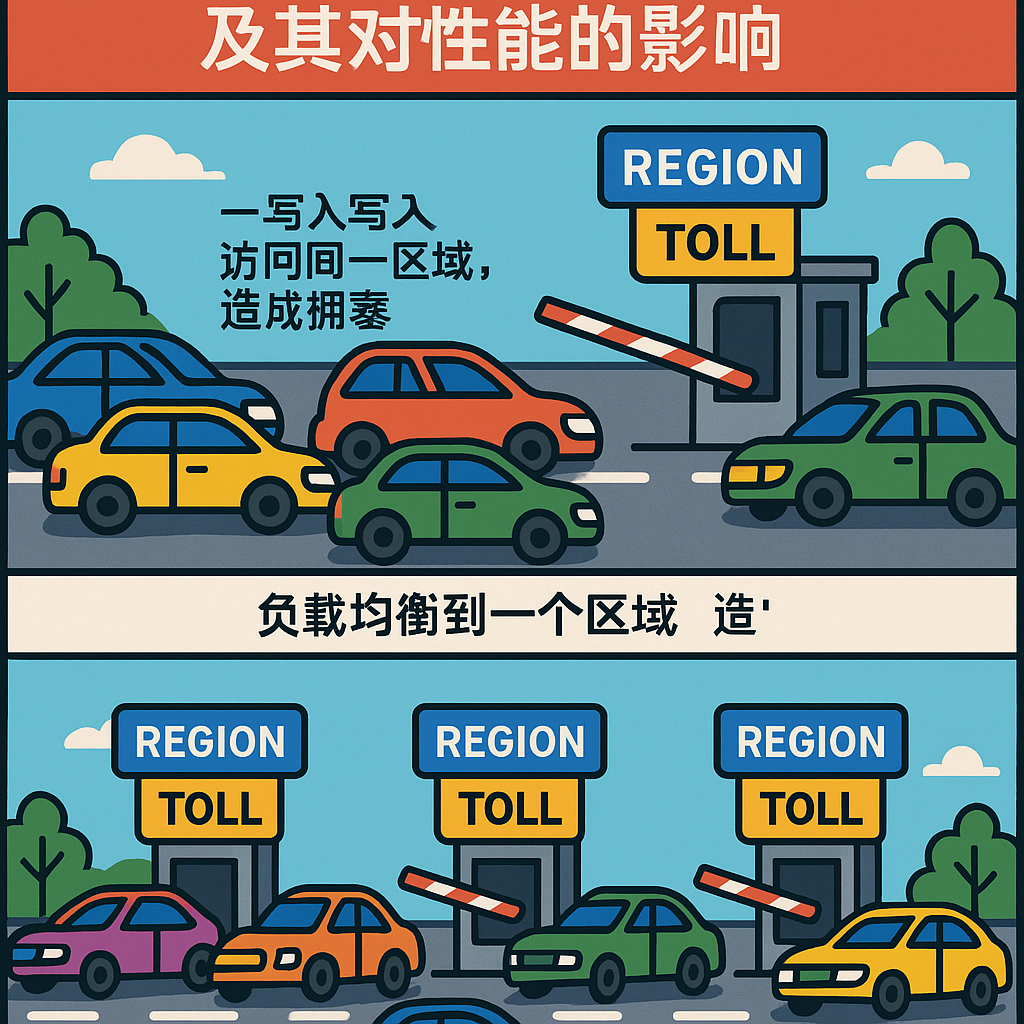
这个灾难性的问题,我们称之为“热点(Hotspotting)”。它会导致单个RegionServer负载过高,性能骤降,甚至宕机。那么,如何避免成为那个只开一个窗口的收费站管理员呢?
RowKey设计的四大原则
一个好的RowKey设计,必须遵循以下四大原则:
- 唯一性原则: RowKey必须唯一,这是基本前提。
- 排序原则: 巧妙利用字典序。比如,想按时间倒序查数据,可以用
Long.MAX_VALUE - timestamp作为RowKey的一部分,这样最新的数据就会排在最前面。 - 散列原则: 核心中的核心!必须让数据均匀地分布在所有Region上,打破RowKey的单调性,避免热点。
- 长度原则: RowKey应尽可能短。过长的RowKey会浪费大量存储和内存空间,影响检索效率。
解决热点的三大策略:加盐、哈希、反转
为了实现散列原则,前辈们总结了三大法宝:
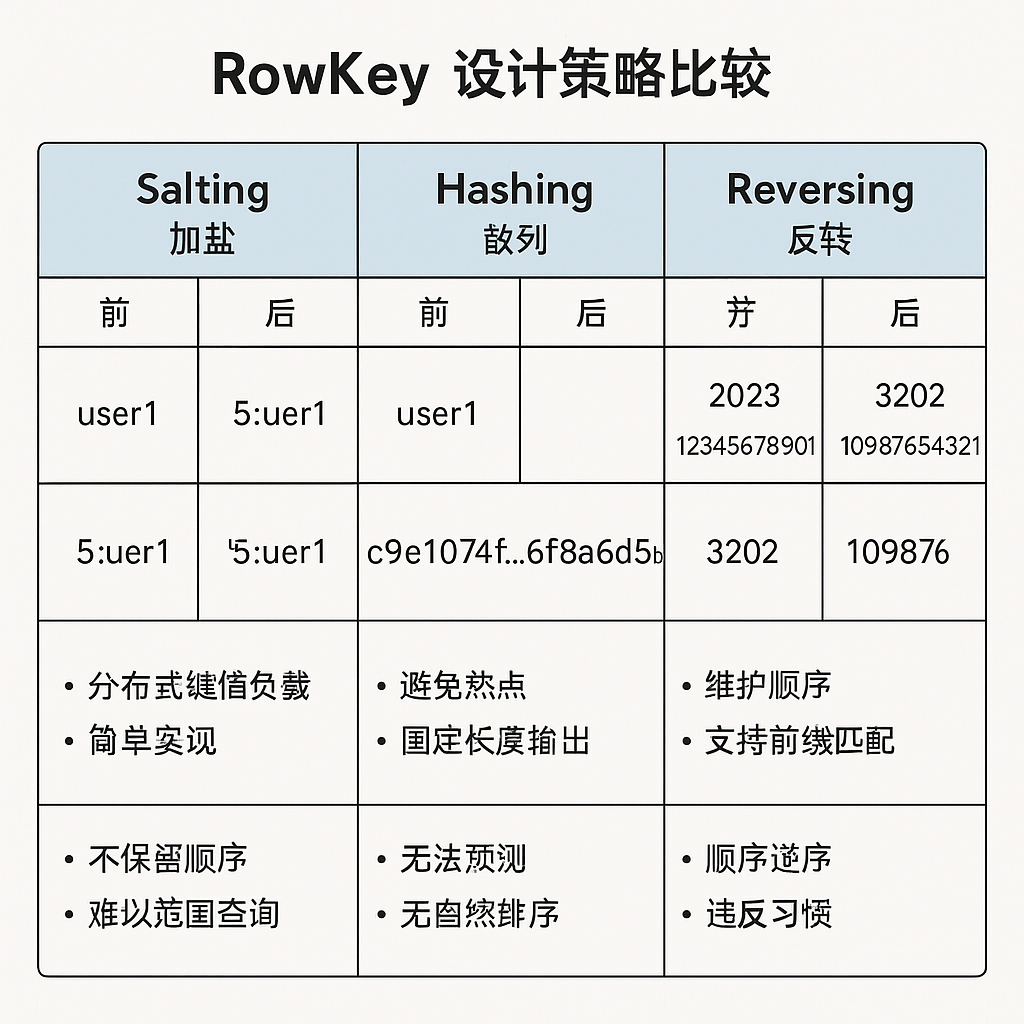
- 加盐 (Salting): 在原始RowKey前面加一个随机前缀。比如,你有4个Region,可以生成0、1、2、3四个前缀(盐),随机拼接到RowKey前。
- 优点: 简单粗暴,效果拔群,能将写入压力均匀分散。
- 缺点: 破坏了RowKey的原始顺序,范围扫描(Scan)会变得非常困难。
- 哈希 (Hashing): 对原始RowKey的某个部分或全部进行哈希(如MD5),用哈希值作为前缀。
- 优点: 散列效果好,而且哈希是确定性的,如果你知道原始值,就能反算出哈希后的RowKey,可以支持精确查询(Get)。
- 缺点: 同样破坏了排序性,不适合范围扫描。
- 反转 (Reversing): 针对固定长度且末尾随机性大的RowKey(如手机号、时间戳),直接将其反转存储。
- 优点: 巧妙地将随机性强的部分前置,实现散列。比如手机号
138...1234反转后变成4321...831,开头就变得随机了。 - 缺点: 牺牲了原始排序性,且只适用于特定格式的RowKey。
- 优点: 巧妙地将随机性强的部分前置,实现散列。比如手机号
专家提示:最佳实践
在实际项目中,常常组合使用这些策略。例如,对于订单数据,可以用 [hash(userId).substring(0,4)] + [userId] + [Long.MAX_VALUE - orderTimestamp] 作为RowKey,既散列了用户,又保证了同一用户的订单按时间倒序排列。
总结:何时拥抱HBase?
经过这一番探索,我们来总结一下:
- HBase是一个面向列族的、稀疏的、分布式的、有序的KV数据库。
- 其“列族式存储”特性使其在读取部分列和数据压缩方面有巨大优势,特别适合“宽表”和“稀疏”场景。
- RowKey是HBase的灵魂,其设计(尤其是散列化)是避免热点、保证高性能的关键。
那么,什么时候应该选择HBase呢?
最适合的场景:
- 需要存储PB级的海量数据,并要求毫秒级的实时随机读写。
- 数据结构不固定,字段稀疏,比如用户画像、行为日志、物联网时序数据。
不适合的场景:
- 需要复杂的事务支持或多表连接(JOIN)的传统OLTP业务。
最后,请记住一句来自HBase老兵的忠告:“在HBase的世界里,没有最好的设计,只有最适合你业务查询场景的设计。请将 ‘为查询而设计 (Design for Read)’ 作为你使用HBase时最重要的座右铭。”

