

HBase 作为一个面向列的、分布式的、可伸缩的 NoSQL 数据库,被设计用于在商用硬件集群上处理海量(PB 级别)的稀疏数据。其核心价值在于能够对庞大的数据集提供实时的随机读写能力。要充分发挥 HBase 的性能,深刻理解其内部数据流转机制至关重要。本文旨在深入剖析 HBase 最核心的生命线——读写流程,从一个客户端请求的发起,历经 RowKey 定位、内存(MemStore/BlockCache)与持久化存储(HFile)的交互,直至最终的数据合并与优化,为您构建一个完整、清晰的 HBase 数据路径知识图谱。
1. HBase 核心架构概览
在深入读写细节之前,我们首先需要理解 HBase 的核心组件及其协作方式。
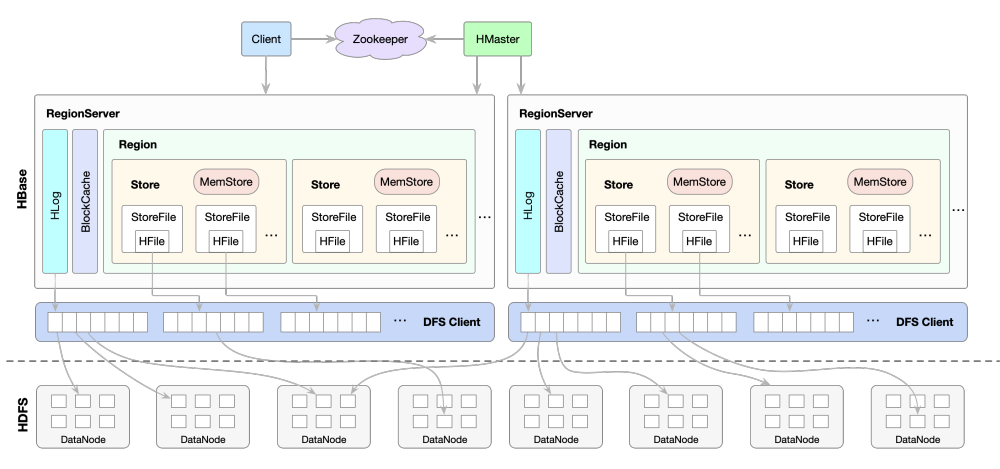
图解: 上图展示了 HBase 的主从架构。客户端通过 ZooKeeper 定位 RegionServer。HMaster 负责集群管理和元数据维护,而 RegionServer 则直接处理数据读写请求,并将数据最终存储在 HDFS 上。
- HMaster: HBase 的“指挥官”,负责管理集群的元数据。其主要职责包括:
- 管理用户表的元信息,例如 Region 的分配、迁移和合并。
- 监控所有 RegionServer 的状态,实现故障转移和负载均衡。
- 关键点:HMaster 不直接参与数据的 I/O 过程,这大大减轻了其负载,使其不易成为系统瓶颈。
- RegionServer: HBase 的“工兵”,是数据操作的实际执行者。其职责包括:
- 存储和管理一个或多个 Region。
- 处理来自客户端的读(Get/Scan)和写(Put/Delete)请求。
- 负责 MemStore 的刷写(Flush)和 HFile 的合并(Compaction)。
- ZooKeeper: HBase 集群的“分布式协调服务”。它为 HBase 提供高可用的状态管理,主要作用有:
- 存储
hbase:meta表的地址,这是客户端定位数据的入口。 - 协调 HMaster 的选举,确保任何时候只有一个活跃的 HMaster。
- 实时监控 RegionServer 的上下线状态。
- 存储
- HDFS (Hadoop Distributed File System): HBase 数据的最终持久化存储层。所有的数据文件(HFile)和预写日志(WAL)都存储在 HDFS 上,这为 HBase 提供了高可靠性和可扩展性的数据存储基础。
2. 深入写流程:从API到持久化
HBase 的写入流程经过精心设计,其核心思想是 “先写日志,再写内存”,通过将随机 I/O 转换为内存中的顺序操作和磁盘上的批量顺序写入,从而实现极高的写入吞吐量。
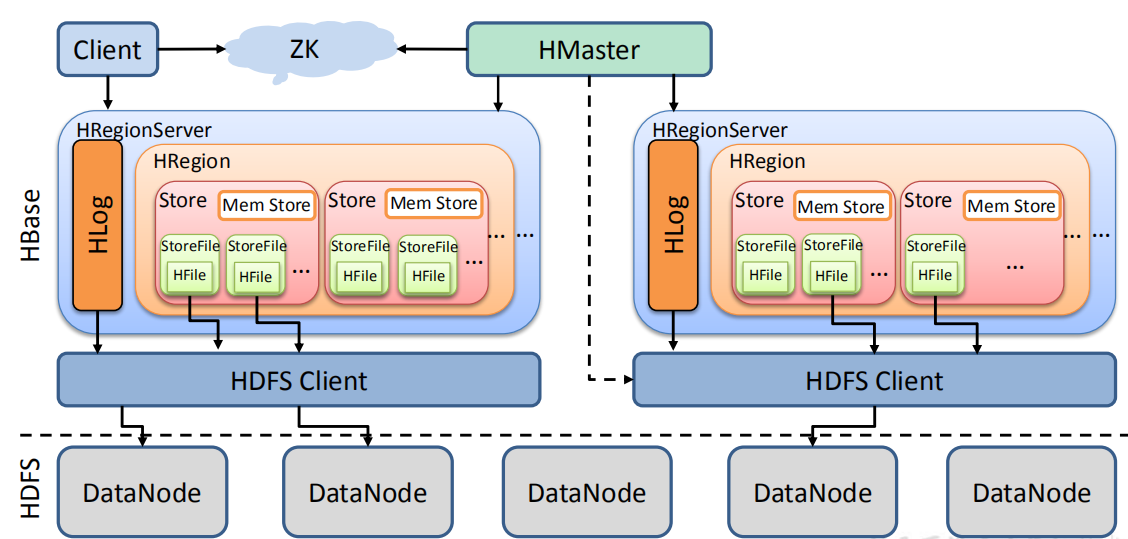
图解: 此图清晰地展示了 HBase 的写数据路径。客户端首先定位到 RegionServer,然后数据被同步写入 WAL 和 MemStore。当 MemStore 达到阈值后,数据会被异步地刷写(Flush)到 HDFS 上的 HFile 中。
整个写流程可分为三个阶段:
阶段一:客户端处理与定位
- 请求定位: 当客户端发起一个
Put请求时,它需要首先确定该数据应该写入哪个 RegionServer。- 客户端连接 ZooKeeper,获取
hbase:meta表所在的 RegionServer 地址。 - 客户端查询
hbase:meta表,根据要写入数据的 RowKey,找到管理该 RowKey 范围的目标 Region 及其所在的 RegionServer。 - 客户端会将这张元数据“地图”缓存起来(Meta Cache),以便后续请求能快速定位,避免重复查询。
- 客户端连接 ZooKeeper,获取
- 本地缓冲 (Client Buffer):
- HBase 客户端提供了一个本地缓冲区。通过设置
autoflush=false,客户端可以将多个Put请求在本地攒批,当缓冲区满或手动调用flushCommits()时,再统一发送给服务器。这种批量提交的方式可以显著减少网络 RPC(远程过程调用)的次数,从而大幅提升写入性能。
- HBase 客户端提供了一个本地缓冲区。通过设置
阶段二:RegionServer 同步写入
当 RegionServer 收到写入请求后,会执行以下两个关键步骤,这两个步骤是同步完成的,以确保数据的可靠性。
- 写入 WAL (Write-Ahead Log):
- 目的: 保证数据不丢失。作为“预写日志”,HBase 会先将这次操作以追加(append)的方式记录到 HDFS 上的日志文件——WAL 中,然后再写入内存。
- 容灾机制: 如果 RegionServer 在数据还未持久化到磁盘文件(HFile)时宕机,HBase 正是通过回放 WAL 中的记录来恢复这些“丢失”的数据。这正是 WAL 的核心作用,在数据恢复时扮演着决定性的角色。
- 写入 MemStore:
- 机制: 数据成功写入 WAL 后,会被放入对应 Region 的 MemStore 中。MemStore 是一个内存中的有序数据结构(通常是跳表 SkipList),它会根据 RowKey、列族、列和时间戳对数据进行排序。
- 低延迟响应: 一旦数据写入 MemStore,RegionServer 就可以向客户端返回成功确认(ACK)。由于整个过程主要基于内存操作,因此写入延迟极低。
阶段三:数据持久化(异步)
- MemStore Flush: 当 MemStore 中积累的数据达到一定阈值时(例如,大小超过
hbase.hregion.memstore.flush.size,默认为 128MB),系统会异步地将其中的数据“刷写”(Flush)到 HDFS,形成一个全新的、只读的数据文件 HFile。此过程对客户端是透明的。
3. 剖析读流程:多层检索与数据合并
相较于写流程,HBase 的读流程更为复杂,因为它需要从可能存在的多个数据源(内存、缓存、多个磁盘文件)中查找数据,并合并成最终结果。
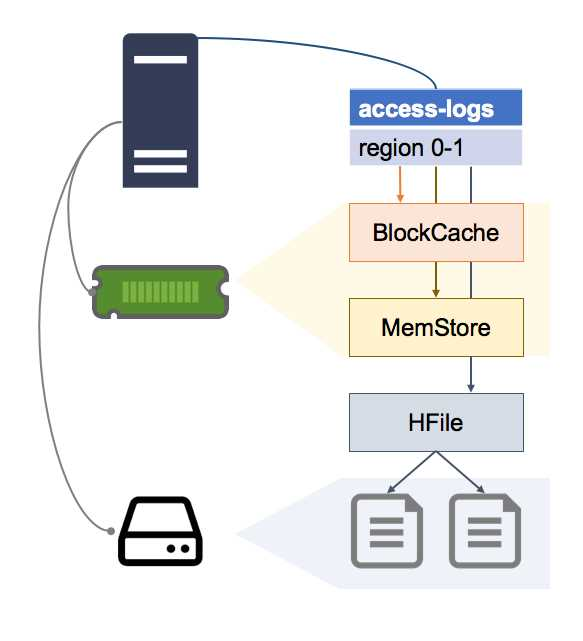
图解: 此图描绘了 HBase 的据检索路径。客户端定位到 RegionServer后,服务器会按照 MemStore -> BlockCache -> HFile 的优先级顺序查找数据。最终,来自不同来源的数据版本会被合并,返回给客户端。
阶段一:客户端定位
与写流程完全相同,客户端首先需要通过 ZooKeeper 和 hbase:meta 表,定位到包含目标 RowKey 的数据所在的 RegionServer。
阶段二:RegionServer 数据检索
HBase 将 Get(单行读取)请求视为一个特殊的 Scan(范围扫描)请求。RegionServer 会构建一个统一的 Scanner 体系,并按照以下优先级顺序进行数据检索:
- MemStore 检索 (最高优先级)
- 首先在 MemStore 中查找数据。因为 MemStore 缓存了最新的写入操作,包括尚未持久化的数据,所以必须最先检查这里,以保证能读取到最新的数据。
- BlockCache 读缓存检索 (次高优先级)
- 如果在 MemStore 中未找到,HBase 会接着检查 BlockCache。BlockCache 是位于 RegionServer 内存中的读缓存,它以 LRU(最近最少使用)策略缓存了从 HFile 中读取的热点数据块(Data Block)。
- 如果 BlockCache 命中,就可以直接从内存中返回数据,从而避免昂贵的磁盘 I/O 操作。
- HBase 支持多层缓存机制,如基于堆内存(On-Heap)的 LRUBlockCache 和支持堆外(Off-Heap)存储的 BucketCache,后者有助于降低 GC 开销,提升高负载下的稳定性。
- HFile 磁盘文件检索 (最低优先级)
- 如果 MemStore 和 BlockCache 均未命中,HBase 只能从磁盘上的 HFile 中读取数据。为了尽可能提高效率,HBase 在此阶段应用了多种优化:
- 布隆过滤器 (Bloom Filter): 每个 HFile 都可以配置布隆过滤器。在访问 HFile 之前,HBase 会先用它来快速判断这个文件是否 可能 包含请求的 RowKey。如果布隆过滤器判定“不存在”,则可以完全跳过对该文件的读取。
- HFile 索引: 如果布隆过滤器判定“可能存在”,HBase 会利用 HFile 内部的多级索引(Index),快速定位到包含目标 RowKey 的数据块(Data Block)在文件中的偏移量。
- 加载数据块: 从 HDFS 读取相应的数据块到内存(并将其放入 BlockCache 以备后续使用),然后在数据块内部通过二分查找等方式精确定位到具体的 KeyValue。
- 如果 MemStore 和 BlockCache 均未命中,HBase 只能从磁盘上的 HFile 中读取数据。为了尽可能提高效率,HBase 在此阶段应用了多种优化:
数据合并与版本过滤
由于 HBase 的“追加式”写入特性(更新即写入新版本,删除即写入删除标记),同一行的数据可能分散在 MemStore 和多个 HFile 中。因此,StoreScanner 的一个核心任务就是将从各处检索到的数据进行 合并。它会根据时间戳进行版本过滤(只保留符合查询条件的最新版本),并处理删除标记(Tombstone),最终将一个完整、正确的数据视图返回给客户端。
4. 数据的持久化与优化:Flush 与 Compaction
随着数据的不断写入,MemStore 会持续刷写成新的 HFile。如果不加管理,大量的小 HFile 会严重影响读取性能。HBase 通过 Compaction(合并) 机制来解决这个问题。
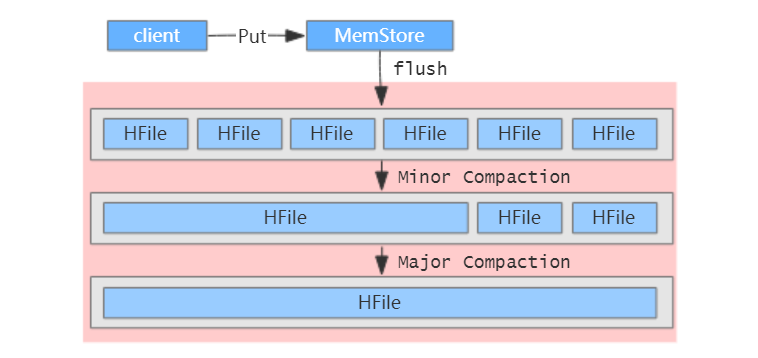
图解: 展示了 Flush 过程,将内存中的 MemStore 数据写入 HDFS 成为 HFile。展示了 Compaction 过程,Minor Compaction 合并部分小文件,而 Major Compaction 则将一个 Store 内的所有 HFile 合并成一个大文件,并进行彻底的数据清理。
- MemStore Flush (刷写)
- 触发时机:
- 当单个 MemStore 的大小达到阈值 (
hbase.hregion.memstore.flush.size)。 - 当一个 Region 内所有 MemStore 的总大小达到阈值。
- 当 RegionServer 级别的 MemStore 占用总内存达到阈值。
- 当 WAL 文件的数量达到上限。
- 手动通过 shell 命令或 API 触发。
- 当单个 MemStore 的大小达到阈值 (
- 过程: 将内存中已经排序好的数据批量写入一个新的、不可变的 HFile 文件中。
- 触发时机:
- HFile Compaction (合并)
- Minor Compaction (小合并):
- 目的: 将数个小的、相邻的 HFile 合并成一个或少量更大的 HFile,以减少文件数量,优化读取性能。
- 特点: 这是一个开销较小、触发频繁的 I/O 操作。它只在参与合并的 HFile 集合内进行数据清理,因此可能无法彻底清除所有已删除或过期的数据。
- Major Compaction (大合并):
- 目的: 将一个 Store(列族)内的 所有 HFile 合并成一个单一的 HFile。
- 特点:
- 彻底清理: 这是唯一能物理删除已标记删除的数据、TTL(存活时间)过期数据和多余版本数据的机会。它能有效回收存储空间,并彻底消除读取路径上的冗余数据。
- 性能影响: Major Compaction 是一个 I/O 和网络开销都极大的操作,可能会对集群性能产生较大影响(被称为“写入放大”,即由于反复合并,原始数据被多次重写到磁盘,放大了实际的 I/O 负载),因此通常建议配置在业务低峰期自动执行,或手动触发。
- Minor Compaction (小合并):
5. RowKey 设计的重要性
在 HBase 中,RowKey 的设计是性能优化的重中之重。因为 HBase 中的数据是严格按照 RowKey 的字典顺序进行物理排序的,所以 RowKey 直接决定了数据的存储分布、检索效率和集群的负载均衡。
RowKey 设计三大原则
- 唯一性原则: RowKey 必须在表中唯一。HBase 将相同 RowKey 的写入视为对该行数据的更新。
- 长度原则: RowKey 应尽可能短,但要保证足够的信息。
- 性能影响: 过长的 RowKey 会显著增加存储开销(每个 KeyValue 都会存储一份 RowKey),并降低 MemStore 和 BlockCache 的内存利用率。推荐长度在 10 到 100 字节之间。
- 核心原则: 保持 RowKey 简短 是首要原则。尽管有建议将长度设计为 8 的倍数以利用内存对齐,但这属于微优化,其效果在现代系统中影响有限。将精力放在保持 RowKey 简短以节省存储和内存空间上,会带来更显著的性能回报。
- 排序原则:
- 巧妙利用 HBase 按字典序排序的特性,可以将经常需要一起读取的数据行设计成连续的 RowKey,这样在进行范围扫描(Scan)时,就可以一次性读取一个连续的数据块,极大提升查询效率。
关键挑战:避免热点 (Hotspotting)
热点问题是指大量的客户端请求集中访问集群中的一个或少数几个 RegionServer,导致这些节点负载过高,而其他节点相对空闲。最常见的诱因是使用单调递增的 RowKey(如时间戳、自增ID),这会导致所有新数据都写入同一个 Region。
避免热点的核心策略是让 RowKey 变得“不那么有序”,从而将写入压力分散到整个集群。
时间戳反转示例: 如果需要频繁查询最新的数据,可以使用 Long.MAX_VALUE - timestamp 作为 RowKey 的一部分。这样,最新的数据(时间戳最大)计算出的值最小,会排在表的最前面,Scan 时可以快速获取。
总结
通过对 HBase 读写流程的深度剖析,我们可以总结出其设计的精髓:
- 写路径: 通过
Client → WAL → MemStore(同步)→ HFile(异步) 的流程,实现了高吞吐、低延迟的写入,并保证了数据的可靠性。 - 读路径: 遵循
Client → MemStore → BlockCache → HFile的多层检索路径,并结合多路归并,确保在复杂的存储结构下也能高效、准确地返回数据。 - 后台优化:
Flush和Compaction机制在后台持续不断地对数据进行整理和优化,动态地在写入性能、读取性能和存储成本之间寻找平衡。 - 性能基石: RowKey 的设计贯穿始终,是决定数据分布、负载均衡和查询效率的根本。
对 HBase 性能的调优,始于对其读写路径的深刻理解。无论是合理的 RowKey 设计与预分区、调整 MemStore 和 BlockCache 的大小,还是优化 Compaction 策略,其最终目标都是根据具体的业务场景,在这条复杂而精妙的数据路径上找到最佳的平衡点。

