


Hadoop 简介
Hadoop 是 Apache 基金会的开源大数据框架,用来在普通商用硬件上构建分布式集群,实现对海量数据的存储和计算。
它的设计核心思想是:让计算移动到数据所在位置,而不是传输数据到计算程序。
对于校招生来说,Hadoop 是大数据领域的入门必备技能,在简历和面试中经常被问到。
Hadoop 1.x vs 2.x 的区别
📌 Hadoop 的版本演进是面试必考点之一。
Hadoop 1.x 特点
- ✅ 核心组件:HDFS + MapReduce
- ✅ JobTracker 负责资源管理和任务调度 → 单点瓶颈
- ✅ NameNode 单点故障,一旦宕机,整个集群不可用
- ✅ 固定 Map/Reduce 槽位,资源利用率低
Hadoop 2.x 改进
- ✅ 引入 YARN(ResourceManager、NodeManager、ApplicationMaster),资源管理与任务调度解耦
- ✅ 支持多框架:不仅 MapReduce,还能运行 Spark、Flink、Tez
- ✅ HDFS Federation:多个 NameNode 分担命名空间,突破扩展瓶颈
- ✅ NameNode 高可用(HA):Active/Standby + ZooKeeper 协调
- ✅ 资源以 Container 为单位动态分配,集群利用率提升到 70%~80%
❓ 常见面试题:
- Hadoop 1.x 与 2.x 的核心区别是什么?
- 为什么 1.x 的 JobTracker 容易成为瓶颈?
- Federation 与 HA 各自解决了什么问题?
核心组件:HDFS、MapReduce、YARN
HDFS
📌 HDFS(Hadoop Distributed File System)是 Hadoop 的分布式文件系统。
- ✅ 架构:NameNode(元数据) + DataNode(数据块)
- ✅ 数据以 Block(默认 128MB)切分存储,并有多副本(默认 3)保证容错
- ✅ 顺序读写性能好,适合批处理
- ✅ NameNode 单点问题在 Hadoop 2.x 通过 HA 与 Federation 改进
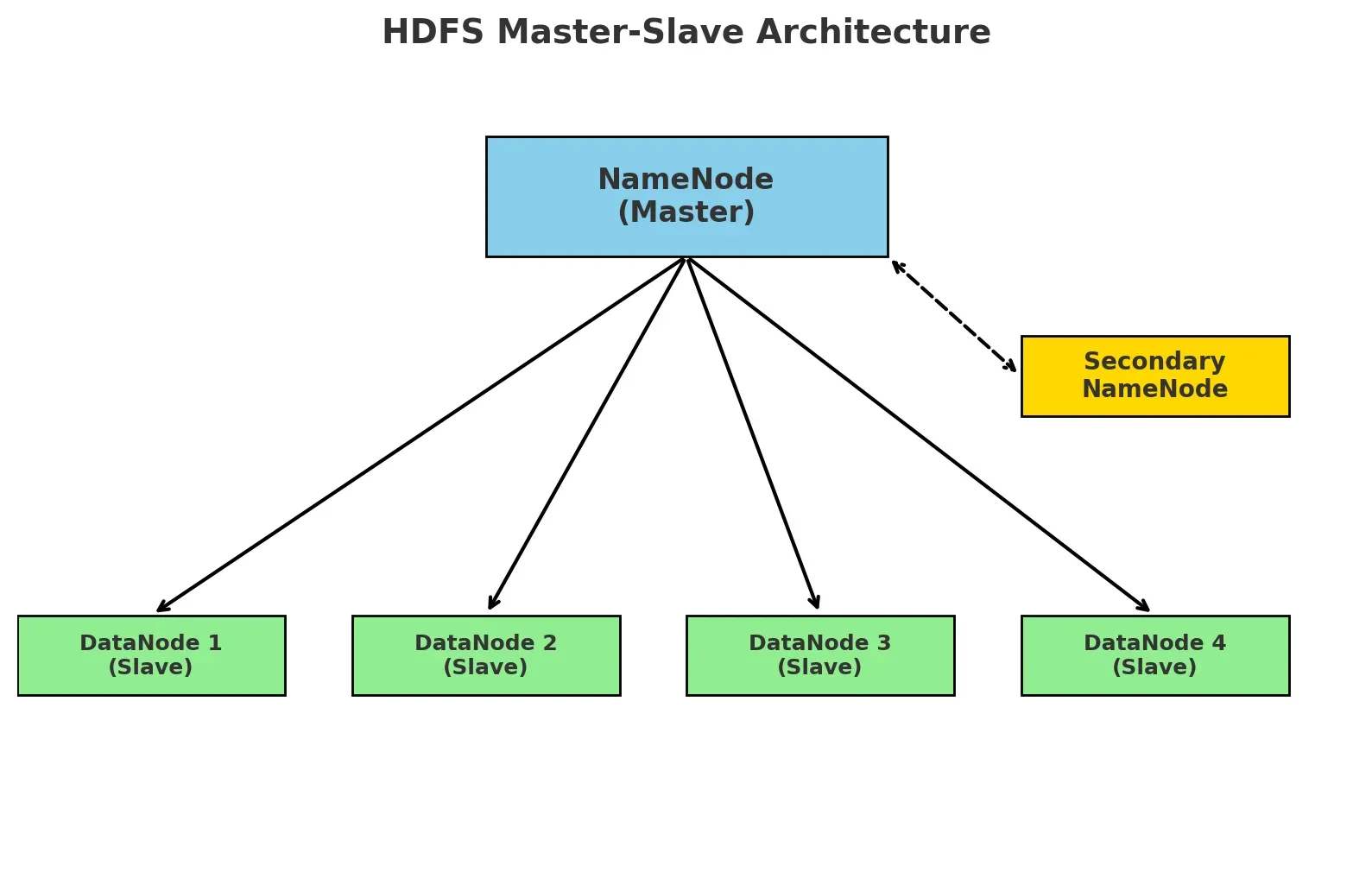
图:HDFS Master-Slave 架构图
这里是一张 HDFS Master-Slave 架构图🔼
- 上方蓝色方块是 NameNode(Master),负责元数据管理
- 右上方黄色方块是 Secondary NameNode,协助做检查点
- 下方绿色方块是多个 DataNode(Slaves),负责实际数据存储
- 箭头表示 NameNode 与 DataNode 的交互,以及 NameNode 与 Secondary NameNode 的元数据同步
MapReduce
📌 MapReduce 是 Hadoop 最初的计算框架,采用 Map(映射)+ Reduce(归约)的并行模型。
执行流程:
- ✅ Map 阶段:输入数据切分 → 并行处理输出键值对
- ✅ Shuffle 阶段:对中间结果按 key 聚合、排序、传输
- ✅ Reduce 阶段:对相同 key 的数据归约计算,输出最终结果
特点:
- ✅ 框架自动完成任务调度、容错、重试
- ✅ 适合批处理,如日志统计、离线分析
- ⚠️ 延迟高,不适合实时计算
- ❓ 常见面试题:请解释 MapReduce 的执行流程,Shuffle 的作用是什么?
图:MapReduce 执行流程图(提示词:MapReduce job execution flow diagram)
YARN
📌 YARN(Yet Another Resource Negotiator)是 Hadoop 2.x 引入的资源管理框架,被称为 Hadoop 的“操作系统内核”。
架构:
- ✅ ResourceManager:全局资源调度
- ✅ NodeManager:节点资源上报与容器管理
- ✅ ApplicationMaster:作业级别的调度器
特点:
- ✅ 统一资源抽象:以 Container 为单位分配资源
- ✅ 支持多框架:Spark、Flink、MapReduce v2 等
- ✅ 多租户调度:支持 Capacity Scheduler / Fair Scheduler
- ✅ 高可用:ResourceManager 可配置 HA
❓ 面试高频:
- YARN 的三个核心角色是什么?
- 为什么 YARN 比 Hadoop 1.x 的调度模型更高效?
图:YARN 架构示意图(提示词:YARN architecture diagram)
Hadoop 与 Spark、Flink 的关系
- ✅ Hadoop MapReduce:适合离线批处理,速度慢
- ✅ Spark:以内存计算加速,适合迭代计算和准实时任务
- ✅ Flink:原生流处理框架,支持亚秒级低延迟
📌 关系:Hadoop 提供 HDFS + YARN 底层支撑,Spark 和 Flink 可以运行在其之上,也可以独立运行。
❓ 常见面试题:
- Spark 和 MapReduce 的区别?
- Flink 在实时计算上的优势?
Hadoop 生态系统简要概览
📌 常见生态组件(面试常考点):
- ✅ Hive:SQL 查询引擎,适合数据仓库、报表
- ✅ HBase:基于 HDFS 的分布式 NoSQL,支持随机读写
- ✅ Kafka:消息队列,用于实时数据管道
- ✅ Flume:日志采集工具,将数据收集到 HDFS/Kafka
- ✅ Sqoop:Hadoop 与传统数据库之间的数据传输工具
- ✅ Oozie:工作流调度系统
- ✅ ZooKeeper:分布式协调服务,支持 NameNode HA、YARN HA
- ✅ Mahout:机器学习库(历史意义大,实际使用已减少)
图:Hadoop 生态系统示意图(提示词:Hadoop ecosystem components diagram)
学习路径建议(校招生)
- 📖 先理解整体架构:HDFS、MapReduce、YARN 的关系
- 📖 掌握核心细节:
- ✅ HDFS:NameNode / DataNode、块、副本、HA
- ✅ MapReduce:执行流程、Shuffle、容错
- ✅ YARN:ResourceManager / NodeManager / ApplicationMaster
- 📖 搭建实践环境:先单节点伪分布,再多节点集群
- 📖 学习生态工具:Hive、HBase、Kafka 等常见组件
- 📖 实战项目:如日志分析 → Flume + HDFS + Hive + Spark
- 📖 面试准备:整理常见问题,能用自己的话解释
常见面试题示例
- ❓ Hadoop 1.x 和 2.x 有何区别?
- ❓ HDFS 的读写流程?
- ❓ NameNode 的单点故障如何解决?
- ❓ MapReduce 的 Shuffle 阶段做了什么?
- ❓ YARN 的核心角色是什么?
- ❓ HDFS 为什么不适合存大量小文件?
- ❓ HDFS 与 HBase 的区别与联系?

