

Yarn 资源调度器
Yarn 是 Hadoop 生态中的资源管理和任务调度平台,负责在集群中协调分布式程序对硬件资源的使用。可以把 Yarn 理解为一层运行在物理服务器之上的“分布式操作系统”,而 MapReduce、Spark 等计算程序则是运行在这套操作系统之上的应用。这一章将介绍 Yarn 的基本架构、工作机制、作业提交流程以及几种常用的调度算法。
1.1 Yarn 基本架构
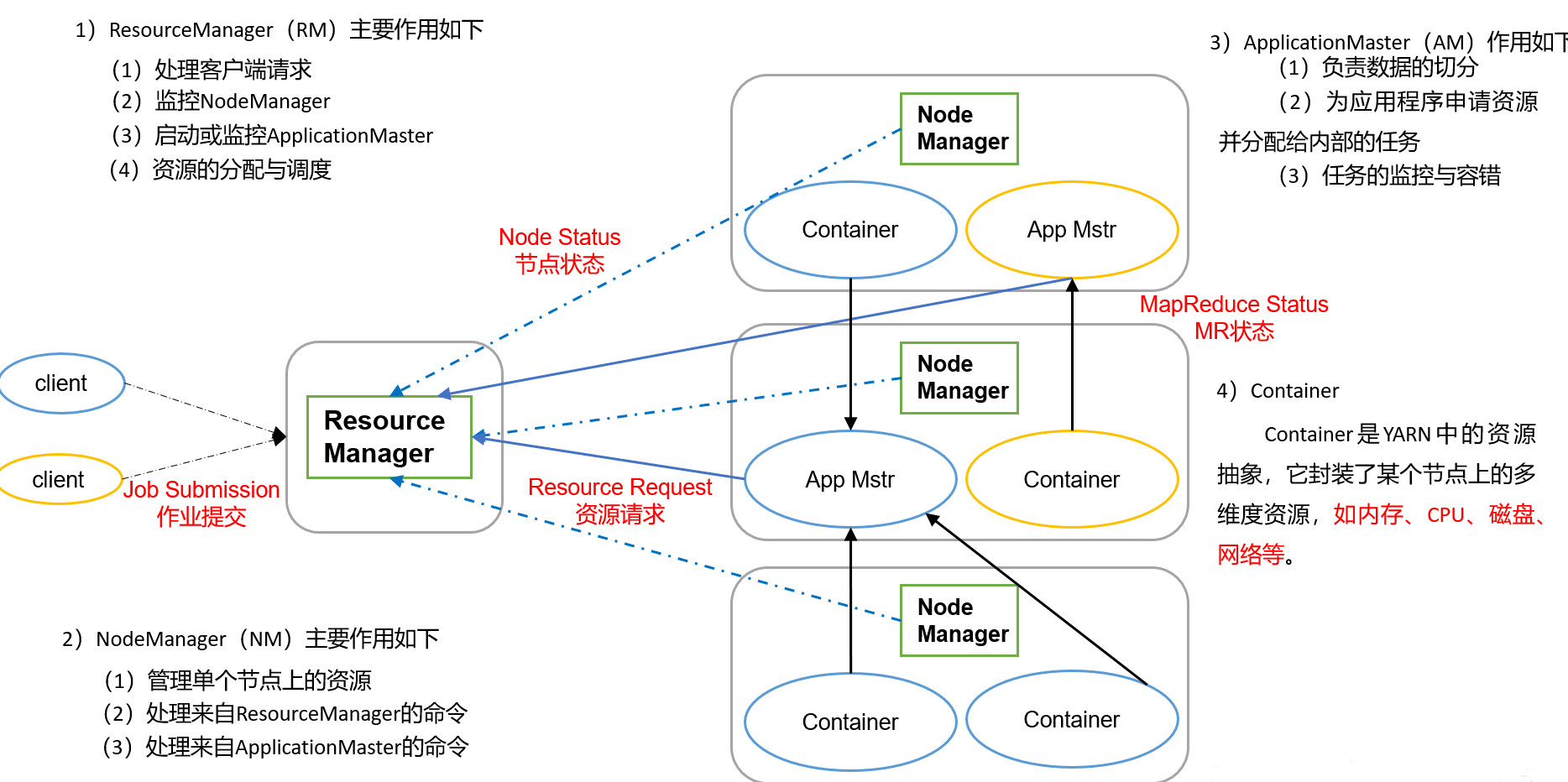
在 Yarn 框架中,有四个核心角色:
| 组件 | 职责与特点 |
|---|---|
| ResourceManager | 负责整个集群的资源管理和分配。它包含两个重要子模块:**调度器(Scheduler)负责根据策略为各个应用分配资源;应用管理器(ApplicationManager)负责接受客户端提交的应用,管理应用的生命周期以及与 NodeManager 的协作。 |
| NodeManager | 运行在每台数据节点上的守护进程,负责监控本机的资源使用情况和容器运行状况,向 ResourceManager 汇报心跳。它还接收 ResourceManager 的指令来启动或停止容器。 |
| ApplicationMaster | 每个提交的应用都会启动一个 ApplicationMaster 负责该应用的调度逻辑。它向 ResourceManager 请求资源(Container),并与各 NodeManager 协作启动具体的任务。随着应用的完成而终止。 |
| Container | Yarn 资源分配的基本单位,包含固定数量的 CPU 核心、内存等资源。ApplicationMaster 向 ResourceManager 申请容器,获得后在 NodeManager 上启动执行任务的进程。 |
上图展示了 Yarn 的基本组件及其关系:ResourceManager 居中协调,NodeManager 部署在各节点上负责执行任务,ApplicationMaster 作为应用的调度者,通过 Container 获取资源运行具体的 Map 或 Reduce 任务。
深入理解
- 资源抽象:Yarn 用 Container 来封装 CPU 和内存等资源,避免了任务直接操纵节点的硬件资源,使得调度粒度更灵活。
- 分层调度:ResourceManager 只负责粗粒度的资源分配,具体的任务调度由 ApplicationMaster 在应用级别自行决定,这种设计消除了单一 JobTracker 的瓶颈,提升了可扩展性。
- 多框架支持:Yarn 并不限于 MapReduce,Spark、Flink 等也可以以 ApplicationMaster 的形式运行,实现统一的资源调度管理。
1.2 Yarn 工作机制
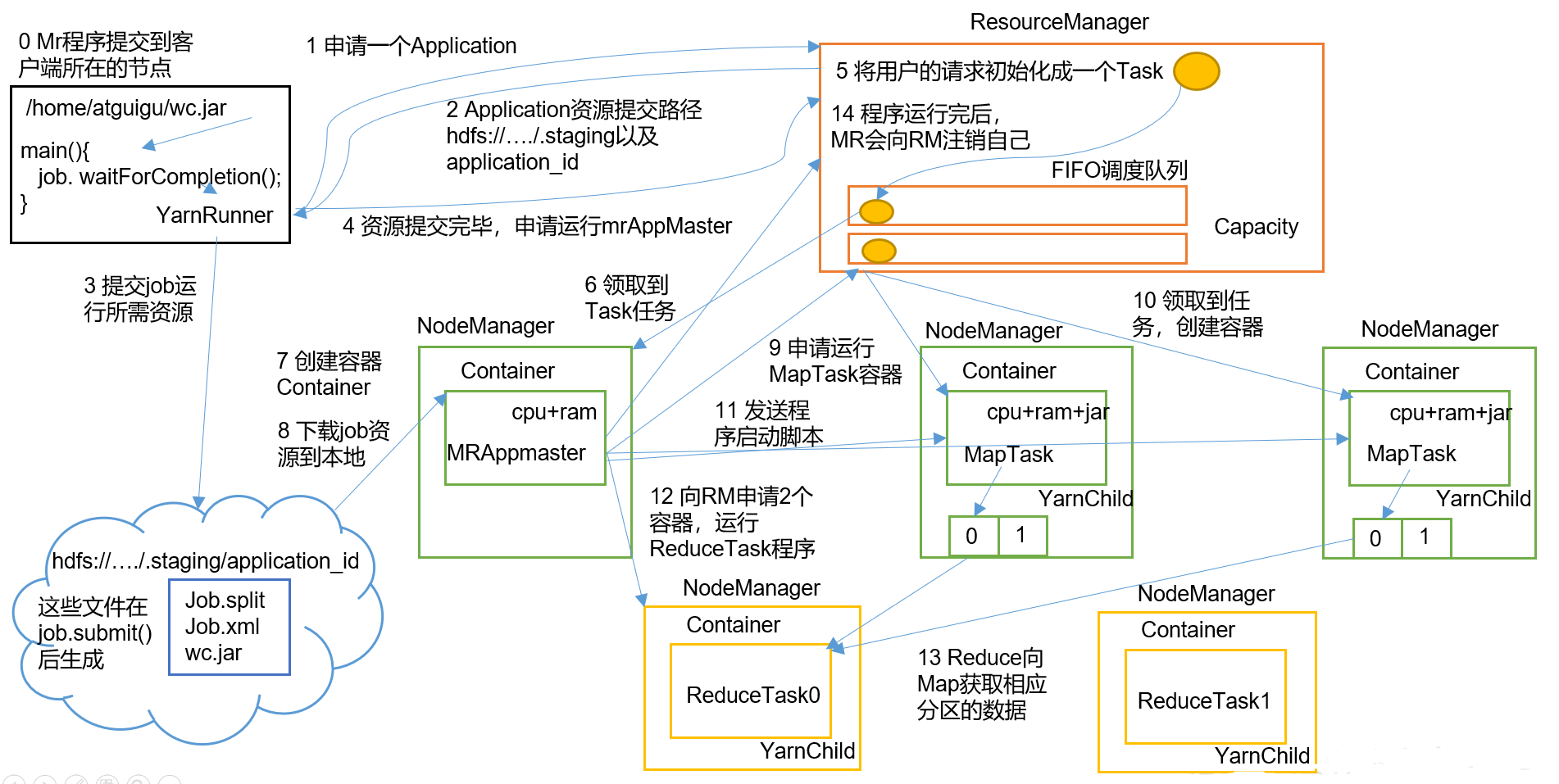
Yarn 的工作流程围绕资源分配和任务执行展开。以提交一个 MapReduce 程序为例,其交互过程可以拆分成以下 15 个步骤:
- 客户端提交作业:用户在客户端节点上提交 MapReduce 程序。
- 申请 Application:YarnRunner 向 ResourceManager 申请一个新的 Application ID。
- 返回资源路径:ResourceManager 返回用于上传程序资源(如 jar 包、配置文件)的 HDFS 路径。
- 上传资源到 HDFS:客户端按照返回的路径将程序 jar 包及切片信息上传到 HDFS。
- 申请启动 ApplicationMaster:资源上传完成后,客户端向 ResourceManager 请求启动应用的 ApplicationMaster。
- 初始化 Task:ResourceManager 将用户请求封装成一个任务条目,加入调度队列。
- 分配到 NodeManager:某个空闲的 NodeManager 拉取该任务条目,准备为 ApplicationMaster 分配容器。
- 创建容器并启动 AM:该 NodeManager 创建一个新的 Container,用于运行 ApplicationMaster。
- AM 下载资源:ApplicationMaster 从 HDFS 下载程序资源到本地。
- 申请 MapTask 容器:ApplicationMaster 根据切片数向 ResourceManager 申请运行 MapTask 的资源。
- 分配容器给 MapTask:ResourceManager 根据调度策略将 MapTask 分配给若干 NodeManager。
- 启动 MapTask:ApplicationMaster 向相应的 NodeManager 发送启动脚本,启动多个 Map 任务。这些任务会对输入数据按键分区、排序。
- 申请 ReduceTask 容器:所有 MapTask 完成后,ApplicationMaster 向 ResourceManager 申请 ReduceTask 的容器。
- 启动 ReduceTask:Reduce 任务从已完成的 MapTask 节点拉取中间结果,完成聚合并写入最终输出。
- 注销应用:所有任务完成后,ApplicationMaster 向 ResourceManager 申请注销自身,释放资源。
这一系列步骤体现了 Yarn 对于应用生命周期的全流程管理。通过把应用拆分为多个阶段,Yarn 可以灵活调度每一步所需的资源,并在资源紧张时与其他应用公平共享集群。
工作机制补充
- 心跳与监控:NodeManager 会定期向 ResourceManager 发送心跳,报告本机资源使用和容器运行状态。失联的 NodeManager 会被标记为失效,ResourceManager 会重新安排任务。
- 容器重试:如果某个 Map 或 Reduce 任务失败,ApplicationMaster 会重新申请容器并重试,保证作业的可靠性。
- 数据本地性优化:在分配 Map 容器时,调度器会优先选择与数据所在节点相同的 NodeManager,实现“计算靠近数据”,减少网络传输开销。
1.3 作业提交全过程
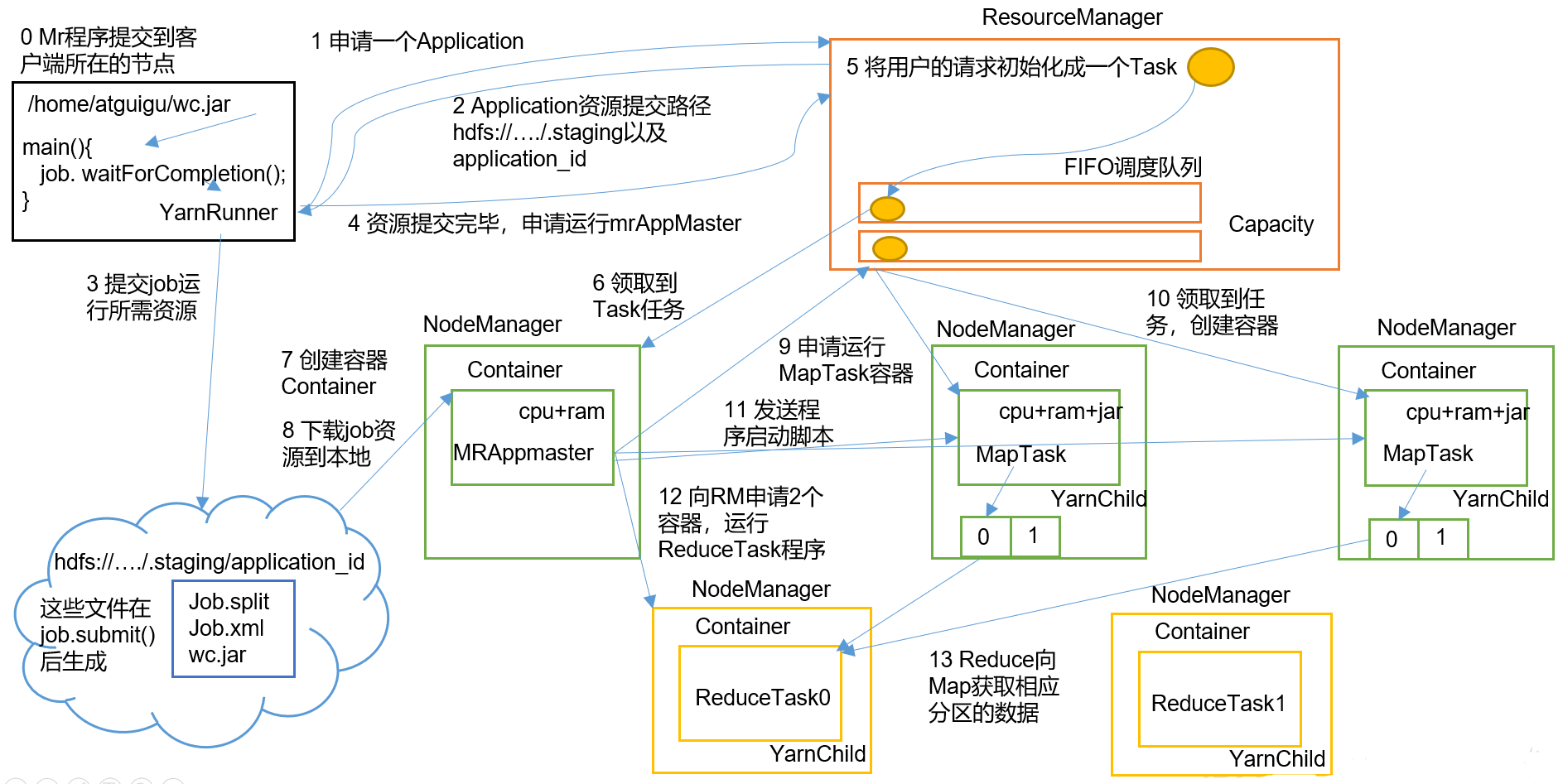
作业提交的完整过程涵盖了作业的启动、初始化、任务分配、执行以及结束阶段。下面以 MapReduce 作业为例,对这些阶段进行更详细的解读:
- 作业提交:
- 客户端通过
job.waitForCompletion()方法向集群提交 MapReduce 作业。 - 客户端向 ResourceManager 申请作业 ID,并获取资源上传路径。
- 客户端将 jar 包、切片信息和配置文件上传至指定 HDFS 路径。
- 上传完成后,再次向 ResourceManager 请求启动 ApplicationMaster。
- 客户端通过
- 作业初始化:
- ResourceManager 接收请求后,将作业放入容量调度器队列。
- 某个空闲的 NodeManager 领取该作业,创建 Container 并启动 ApplicationMaster。
- ApplicationMaster 下载客户端上传的资源,为后续任务调度做好准备。
- 任务分配:
- ApplicationMaster 根据切片数目向 ResourceManager 申请 MapTask 的容器资源。
- ResourceManager 根据调度策略将任务分配给多个 NodeManager,并为每个任务创建相应的 Container。
- 任务运行:
- ApplicationMaster 启动各个 MapTask,任务负责对输入数据分片进行处理、分区和排序。
- Map 阶段完成后,ApplicationMaster 再次申请 ReduceTask 的容器资源。
- Reduce 任务从 Map 节点拉取中间结果,执行聚合并输出最终结果。
- 进度和状态更新:
- Yarn 框架持续把任务的进度和状态(包括计数器信息)返回给 ApplicationMaster,客户端通过轮询查看作业状态。
- 这些参数如
mapreduce.client.progressmonitor.pollinterval和mapreduce.client.completion.pollinterval可以调整状态检查的频率。
- 作业完成:
- 当全部任务完成时,ApplicationMaster 和其启动的所有 Container 进行清理。
- 作业信息会被作业历史服务器保存,供用户查阅。
- 最终,资源被释放,作业结束。
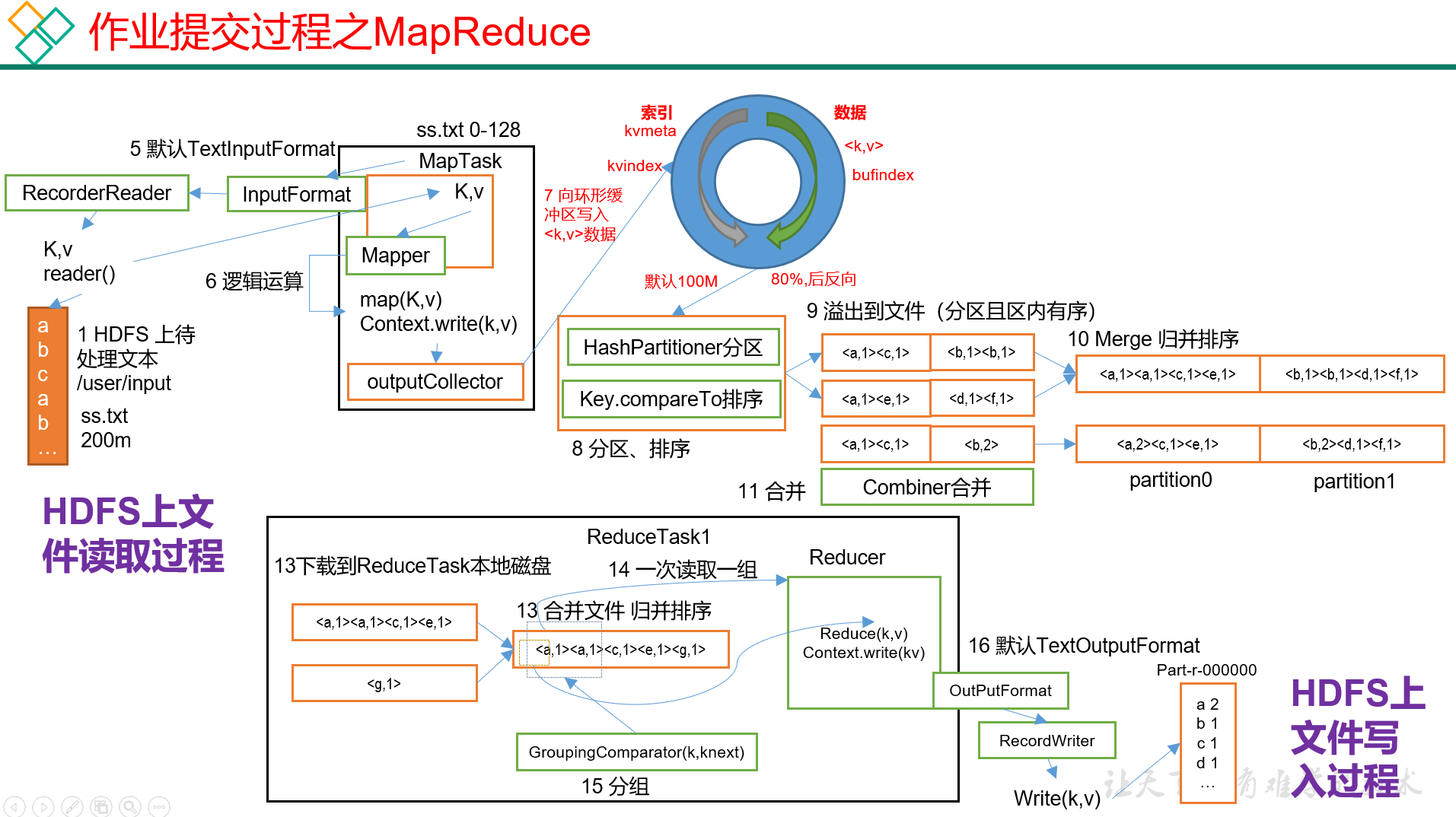
通过划分阶段,作业提交全过程让我们看到 Yarn 如何协调各个组件的配合,以及 ResourceManager、ApplicationMaster、NodeManager 之间的职责划分。
1.4 资源调度器
Hadoop Yarn 为多租户环境提供了三种常用的调度策略:先进先出调度器 (FIFO)、容量调度器 (Capacity Scheduler) 和 公平调度器 (Fair Scheduler)。不同的调度策略适用于不同的使用场景,下面逐一介绍。
1.4.1 先进先出调度器(FIFO)
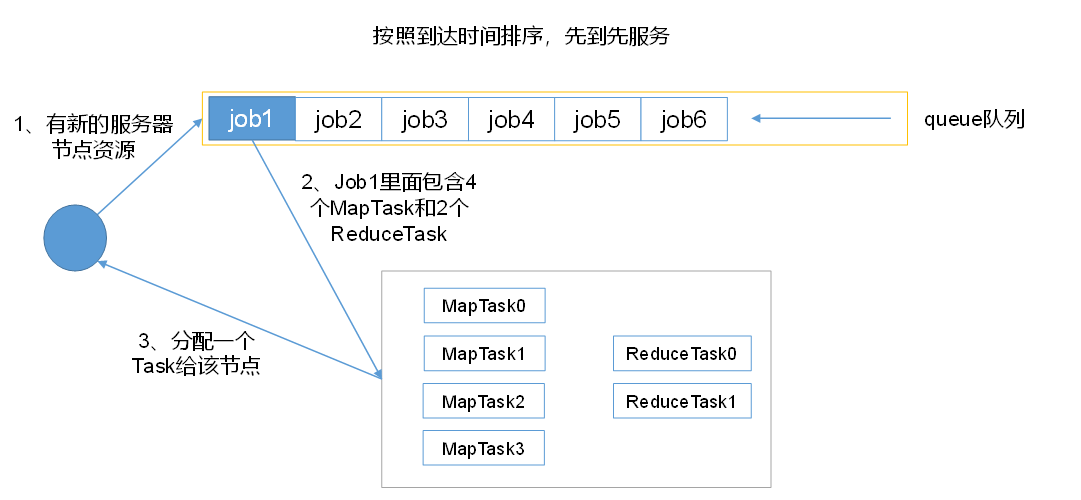
FIFO 调度器是 Hadoop 最早提供的调度方式。它只有一个全局队列,所有作业按照提交顺序依次执行。这种方式简单,但在多用户和多类型作业混合的环境下存在明显缺陷:
- 缺乏灵活性:所有作业排队等待,无法根据作业类型和资源需求合理排期。
- 资源利用率低:长作业占满集群时,短小任务必须等待,造成资源空闲浪费。
- 不满足服务质量:不同业务对响应时间的要求不同,单队列无法保证高优先级业务快速运行。
尽管 FIFO 策略适合早期以批处理为主的集群,但随着日志分析、机器学习、交互式查询等多样化应用出现,单一的 FIFO 已无法满足实际需求。
1.4.2 容量调度器(Capacity Scheduler)

Capacity Scheduler 最初由 Yahoo! 开发,用于解决多租户环境下资源公平和利用率的问题。其核心思想是:把集群资源划分为多个逻辑队列,每个队列可以设置最低保障容量和使用上限。主要特点包括:
- 容量保证:管理员可以为每个队列配置资源保障和上限,队列内的应用共享这部分资源。
- 灵活共享:当某个队列暂时用不满资源时,其闲置资源可以暂时借给其他队列;当队列有新的应用提交时,这些资源将归还。
- 多租户支持:队列层次可以反映组织或业务结构,实现不同团队的资源隔离;管理员可以限制单个用户或单个应用的最大任务数,防止“资源霸占”。
- 安全控制:每个队列可以配置访问控制列表 (ACL),限制谁可以提交应用、谁可以查看和操作应用。
- 动态配置:大多数配置可以在不重启集群的情况下动态调整,让运维更灵活。
容量调度器适用于用户数量多、作业类型复杂的企业环境,它保证各业务线“吃饱”但又不相互影响,是 Hadoop3.x 默认使用的调度策略。
1.4.3 公平调度器(Fair Scheduler)(了解)
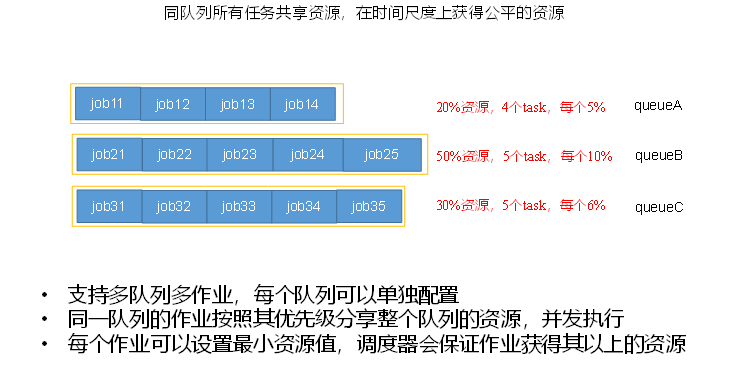
公平调度器最初由 Facebook 开发,旨在让所有作业在时间维度上获得大致相等的资源。与容量调度器的区别在于公平调度器更关注作业之间的实时公平,适合有大量短作业需要快速响应的场景:
- 资源公平共享:每个队列可以选择 FIFO、Fair 或 DRF (Dominant Resource Fairness) 三种策略分配资源。Fair 为默认策略,依据最大最小公平算法,让所有任务尽量同时前进;DRF 则考虑了 CPU、内存等多维资源,使资源分配更加合理。
- 支持资源抢占:当队列出现饥饿情况时,Fair Scheduler 可以强制回收其他队列过量使用的资源,提高整体吞吐。
- 提升小作业响应:公平调度器通过动态调整资源份额,让小作业能够尽快完成,而不至于被大作业长时间挤压。
公平调度器的灵活性很高,但配置相对复杂,适合需要支持实时分析和交互式查询的集群。
2 容量调度器多队列提交案例
在使用容量调度器的默认配置时,整个 Yarn 集群只有一条 default 队列。所有作业提交到这一条队列上,不同类型的任务混合排队,会导致单个任务阻塞整个队列;同时随着业务增长,也需要按业务线限制集群使用率,做到资源隔离和公平共享。因此,实际生产中常常会把容量调度器配置成多条任务队列raw.githubusercontent.com。
2.1 需求
为什么需要配置多条队列?主要原因包括:
- 避免任务相互阻塞:默认的单队列模式下,当某个大任务在队列前端占据大量资源时,后续的短任务必须等待,导致资源利用率不高。通过把不同业务的作业放入不同队列,可以防止互相干扰。
- 限制业务使用率:随着公司业务增长,不同部门对集群资源的需求不同,通过为每条队列设置容量和上限,可以限制某个业务过度占用资源,保证整体公平。
- 实现资源隔离:多队列可以映射到不同业务线,管理员可以对每个队列的用户、作业优先级等进行粒度控制,还可以给队列单独配置 ACL、最大并发作业数等安全策略。
下面以一个“Default + Hive”双队列的例子,演示如何配置容量调度器并向新队列提交任务。
示意图:单队列与多队列
# 单队列模式:所有任务都进入 default 队列
┌──────────────┐ │ default │
job1, job2 ─▶ queue │
└──────────────┘# 多队列模式:按业务划分 default 和 hive 队列
┌──────────────┐ ┌──────────────┐ │ default │ │ hive │
批处理任务──▶ queue │ │ queue │
└──────────────┘ └──────────────┘
2.2 配置多队列的容量调度器
Yarn 的队列配置文件为 capacity-scheduler.xml,在其中可以声明多个子队列并为每个队列设置容量和权限。以下为添加 hive 队列的核心配置说明(仅展示关键参数,具体路径和 XML 格式略):
| 配置项 | 作用 | 示例值 |
|---|---|---|
yarn.scheduler.capacity.root.queues | 定义根队列下的子队列列表,多个队列用逗号分隔。 | default,hive |
yarn.scheduler.capacity.root.default.capacity | default 队列的最低保障容量(%)。 | 40 |
yarn.scheduler.capacity.root.default.maximum-capacity | default 队列的最大可用容量(%),超过部分会被其他队列借用。 | 60 |
yarn.scheduler.capacity.root.hive.capacity | hive 队列的最低保障容量。 | 60 |
yarn.scheduler.capacity.root.hive.user-limit-factor | 单个用户最多可使用的队列份额倍数,1 表示最多占用该队列全部资源。 | 1 |
yarn.scheduler.capacity.root.hive.maximum-capacity | hive 队列的最大容量,省略表示默认为 100%。 | 100 |
yarn.scheduler.capacity.root.hive.state | 队列状态,RUNNING 表示可用;STOPPED 表示暂停接收作业。 | RUNNING |
yarn.scheduler.capacity.root.hive.acl_submit_applications | 可以向 hive 队列提交作业的用户或组,* 表示所有人。 | * |
yarn.scheduler.capacity.root.hive.acl_administer_queue | 可以管理队列(如停止、修改)的用户或组。 | * |
设置这些参数的步骤:
- 打开
capacity-scheduler.xml,在<configuration>标签中添加或修改上述属性。确保根队列各子队列capacity总和为 100%,否则会引发 Yarn 启动失败。 - 调低
default队列的容量,让出部分资源给hive队列。同时为新队列设置user-limit-factor、maximum-capacity等限制,防止单用户过度占用。 - 保存文件后,无需重启 ResourceManager,可以通过以下命令刷新队列配置:yarn rmadmin -refreshQueues
这条命令会使 ResourceManager 重新加载capacity-scheduler.xml的内容,使得新的队列配置立即生效。
队列设计建议
- 容量划分:根据业务重要性和资源需求分配队列容量,保障关键业务资源充足。
- 最大容量:设置
maximum-capacity大于capacity,允许闲置资源暂时借出,提高整体资源利用率。 - 用户限制:利用
user-limit-factor和 ACL 控制单个用户的使用上限,避免“资源霸占”。 - 队列状态:可以将不常用的队列设置为
STOPPED,在需要时再启用。 - 动态调整:容量调度器支持在线修改配置,但仍需审慎规划,避免频繁变动导致调度不稳定。
2.3 向 Hive 队列提交任务
修改完成并刷新队列后,新建的 hive 队列已经可以接受作业。默认情况下,MapReduce 程序会提交到 default 队列。要将作业提交到指定队列,需要在作业的 Configuration 中设置 mapreduce.job.queuename 属性。下面是一段示例代码,演示如何将 WordCount 作业提交到 hive 队列:
public class WcDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 指定队列名称为 hive
conf.set("mapreduce.job.queuename", "hive");
// 创建 Job 实例
Job job = Job.getInstance(conf);
job.setJarByClass(WcDriver.class);
// 设置 Mapper 和 Reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
// 设置输出键值类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交任务并等待完成
boolean success = job.waitForCompletion(true);
System.exit(success ? 0 : 1);
}
}代码解读:
- 通过
conf.set("mapreduce.job.queuename", "hive")指定了队列名。没有此设置时,作业默认提交到default队列。 - 其余代码与普通 MapReduce 作业相同:创建
Job、设置 Mapper/Reducer、指定输出类型和输入输出路径,最后调用waitForCompletion(true)提交作业。 - 只要队列名存在且状态为
RUNNING,Yarn 就会在相应队列中调度资源执行该作业。
提交完成后,可以通过 Yarn Web UI 或命令行工具查看作业所在队列,验证作业确实分配到了 hive 队列。

