

1. 引言:开启流处理新范式
Flink 简介与定位
Apache Flink 是一个为有界和无界数据流提供有状态计算的开源流处理框架。自诞生以来,Flink 凭借其高吞吐、低延迟、高可用性的核心优势,在实时计算领域占据了举足轻重的地位。它不仅仅是一个流处理引擎,更是一种全新的数据处理哲学。
核心议题引入
要真正理解 Flink 的强大之处,必须从其最核心的两个概念入手:有界流 (Bounded Streams) 与 无界流 (Unbounded Streams)。这两个概念是 Flink 设计哲学的基石,也是其实现“流批一体”这一颠覆性架构的理论基础。
文章结构预告
本文将循序渐进,从基础概念的定义出发,深入剖析支撑 Flink 统一处理模型的四大技术基石(时间、水位线、状态、检查点),通过实践案例展示其 API 的统一性,最后在架构层面探讨“流批一体”带来的战略优势。
2. 基础概念:定义数据流的边界
在 Flink 的世界观里,一切数据皆为流。不同之处仅在于流是否有一个明确的终点。
定义有界流 (Bounded Streams)
- 概念:有明确开始和结束的数据集。可以将其想象成一个文件中的所有行、数据库中的一张表或一个固定的数据集。
- 特征:数据量是有限的,可以在处理前知晓其全部内容。因此,可以等待所有数据到达后进行一次性计算,这正是传统的批处理 (Batch Processing) 模式。
- 类比:历史销售记录文件、特定日期的网站访问日志。
定义无界流 (Unbounded Streams)
- 概念:有明确的开始,但没有定义的结束。数据会随着时间的推移持续不断地生成。
- 特征:数据量是无限的,无法预知其终点。因此,数据必须被持续地、近乎实时地处理,这便是流处理 (Stream Processing) 模式。
- 类比:实时用户行为日志、物联网设备的传感器读数、金融市场的交易数据。
核心特性对比
为了更清晰地区分这两种数据流,我们可以从数据量、处理时机、处理模式等多个维度进行对比。
[此处插入:有界流与无界流特性对比表]
| 特性 | 有界流 (Bounded Stream) | 无界流 (Unbounded Stream) |
|---|---|---|
| 数据量 | 有限、已知 | 无限、持续增长 |
| 结束点 | 有明确的结束 | 无明确的结束 |
| 处理模式 | 批处理 (Batch Processing) | 流处理 (Stream Processing) |
| 处理时机 | 可等待所有数据到达后一次性处理 | 必须持续、实时地处理 |
| 数据排序 | 可对整个数据集进行全局排序 | 通常只能在时间窗口内局部排序 |
| 典型场景 | 历史数据分析、批量ETL、离线报表 | 实时监控、欺诈检测、在线推荐 |
解读:此表格清晰地揭示了两种数据流的本质区别。有界流的“有限性”使其适用于离线分析,而无界流的“无限性”则要求必须采用持续处理的范式。Flink 的精妙之处在于,它用一套统一的模型来涵盖这两种看似截然不同的场景。
3. 原理机制:Flink 的技术基石
Flink 之所以能优雅地统一处理有界与无界流,离不开其底层的四大核心技术支柱:时间概念、水位线、状态管理和检查点。
A. 时间概念 (Time Concepts):理解事件的生命周期
为什么需要多种时间? 在分布式系统中,一个事件从产生到被处理,会经历网络传输、消息队列缓冲等多个环节,导致其“发生时间”和“处理时间”存在差异。为了应对这种不确定性,Flink 提供了三种时间概念。
- 事件时间 (Event Time)
- 定义:事件在源头设备上实际发生的时间,通常作为时间戳内嵌于数据记录中。
- 价值:它提供了对事件发生顺序的真实描述,是处理乱序数据、保证计算结果准确性和确定性的关键。
- 处理时间 (Processing Time)
- 定义:数据在 Flink 计算算子中被处理时的机器系统时间。
- 价值:实现最简单,延迟最低。但由于受系统负载和网络抖动影响,计算结果具有不确定性,同一份数据在不同时间运行可能得到不同结果。
- 摄入时间 (Ingestion Time)
- 定义:数据进入 Flink Source 算子时的时间。
- 价值:它是事件时间和处理时间的一种折衷。比处理时间更可预测,但无法完美处理在进入 Flink 之前就已发生的乱序。
[此处插入:Flink时间概念图]
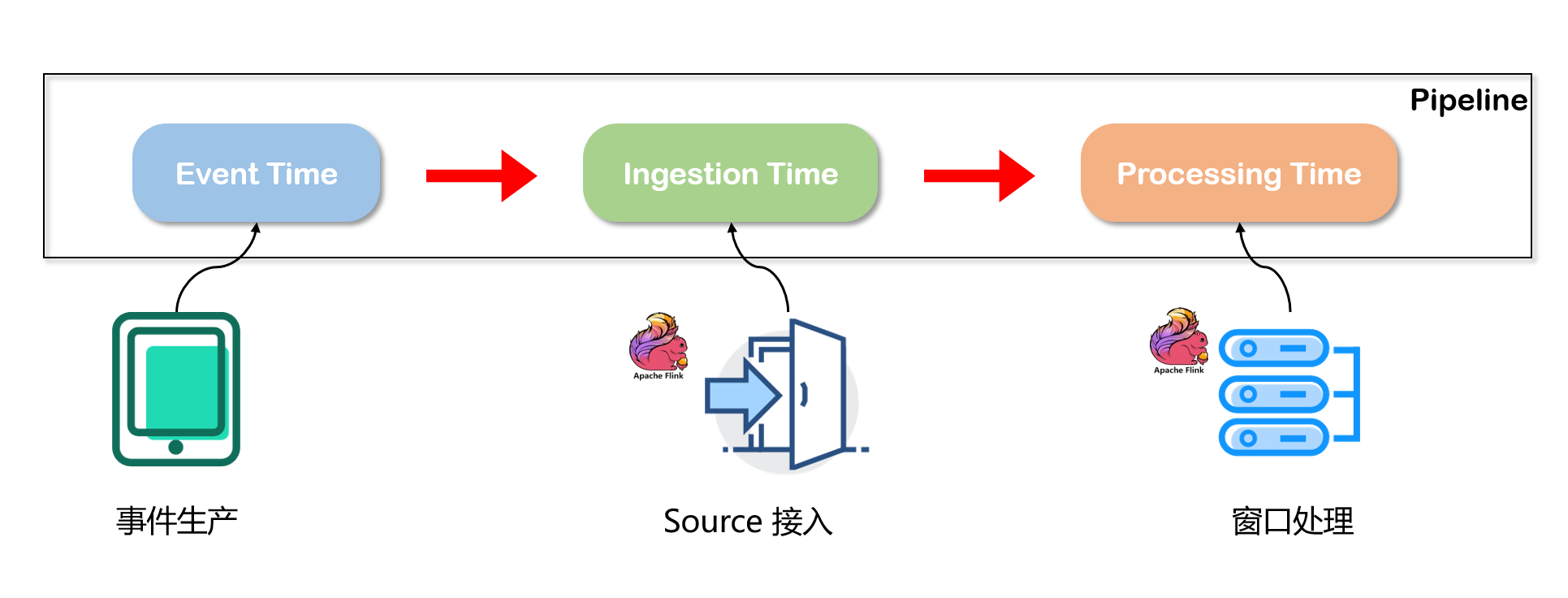
解读:上图直观地展示了一个数据从产生到被处理所经历的三个关键时间点。事件时间是最早的,反映了业务的真实情况;摄入时间和处理时间则依次递延。Flink 允许开发者根据业务需求选择最合适的时间语义。
B. 水位线 (Watermarks):驾驭乱序数据
水位线解决了什么问题? 在事件时间模式下,由于网络延迟等原因,数据并不会严格按照其发生时间的顺序到达。水位线就是 Flink 用来应对数据乱序和延迟的核心机制。
- 定义与作用:水位线 (Watermark) 是一个插入到数据流中的特殊时间戳标记(Watermark(t)),它代表“事件时间已经推进到 t,所有时间戳小于等于 t 的数据都应该已经到达了”。这是一种系统对于事件时间进展的宣告。
- 工作原理:
- 生成:水位线通常基于数据流中的事件时间戳生成。一种常见的策略是“当前观察到的最大事件时间戳减去一个允许的乱序延迟时间”。这个延迟时间代表了系统愿意为乱序数据等待多久。
- 传播:水位线像普通数据一样在算子之间流动,并驱动所有算子的事件时间时钟前进。
- 触发计算:当一个算子(如窗口)接收到一个水位线 Watermark(t) 时,它会认为所有结束时间小于 t 的窗口都已经收到了全部数据,从而触发这些窗口的计算。
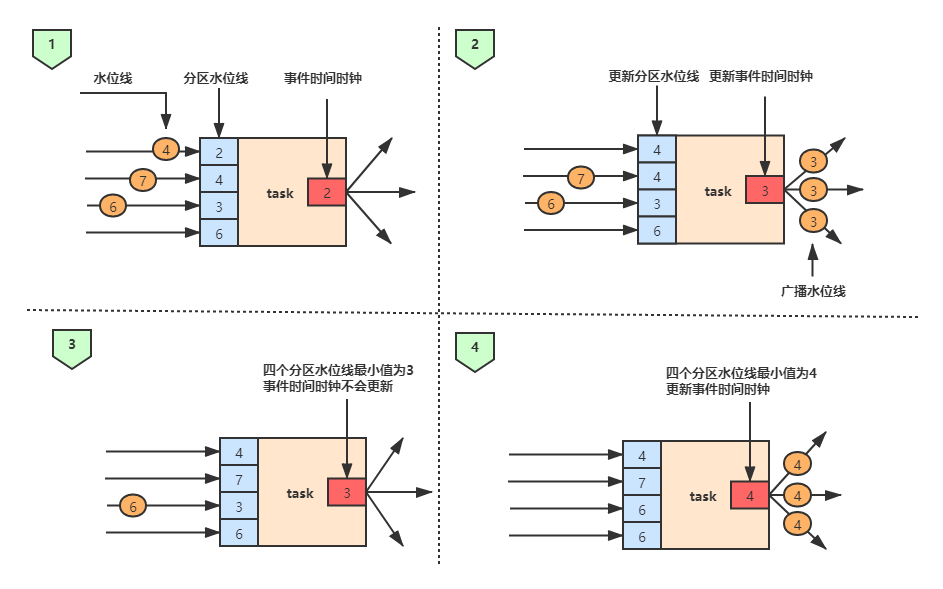
解读:上图展示了 Flink 水位线的计算逻辑:全局水位线取决于所有分区中最小的水位线,这一机制既能保证事件时间的正确性,也可能造成下游的延迟等待。
图解说明:Flink 水位线传播机制
1. 初始阶段(左上角)
水位线来源:不同分区的流数据源会发出水位线(Watermark),例如 2, 4, 3, 6。
分区水位线:Flink 会分别记录每个分区的水位线。
事件时间推进:算子(task)只能根据 最小的分区水位线 来更新整体的事件时间。因此这里算子接收的全局水位线是 2。
👉 启发:全局水位线 = 所有分区水位线的最小值。
2. 水位线更新(右上角)
某个分区的水位线更新为 4。
Flink 会重新计算四个分区的最小值,此时是 3。
于是 task 的事件时间推进到 3,并向下游广播水位线 3。
👉 注意:即使部分分区的水位线更新到 4,但因为还有分区是 3,所以全局只能推进到 3。
3. 停滞情况(左下角)
某些分区可能长时间没有新的数据到来(水位线不更新)。
比如某个分区还停留在 3,那么全局水位线会一直卡在 3。
即便其他分区的水位线更新到更大值,也不会推进。
👉 这也是 Flink 里常见的「水位线停滞」问题。
4. 继续推进(右下角)
当最后一个落后的分区水位线也更新为 4。
此时全局最小值变为 4,算子就可以把水位线推进到 4,并向下游广播。
C. 状态管理 (State Management):让计算拥有记忆
- 概念:状态 (State) 是算子在处理数据时需要“记住”的信息。例如,在进行 SUM 聚合时,当前的总和就是一种状态;在窗口计算中,窗口内缓存的所有数据也是一种状态。
- 重要性:有状态计算是复杂流处理的根基。没有状态,计算就只能局限于单个事件,无法实现聚合、窗口、模式检测等高级逻辑。同时,状态也是 Flink 实现容错和精确一次 (Exactly-Once) 处理语义的基础。
- 核心组件:Flink 提供了丰富的状态类型(如 ValueState, ListState)和可插拔的状态后端 (State Backend),如 RocksDBStateBackend,它能将状态持久化到磁盘,从而支持超大规模的状态存储。
D. 检查点 (Checkpoints):保障容错与一致性
- 机制:检查点 (Checkpoint) 是 Flink 容错机制的核心。它通过一种分布式快照算法(类 Chandy-Lamport 算法),周期性地将整个应用所有算子的状态持久化到远程存储(如 HDFS 或 S3)中。
- 工作流程:JobManager 会向数据源注入一种名为 Checkpoint Barrier 的特殊消息。这个 Barrier 会随数据流在算子间传递。当一个算子收到 Barrier 时,它会立刻保存自己当前的状态快照,然后再将 Barrier 转发给下游。
- 核心价值:
- 容错性:当作业因故失败时,Flink 可以从最近一次成功的 Checkpoint 恢复所有算子的状态,然后从数据源的相应位置重新消费数据,从而保证数据不丢失。
- 一致性:Checkpoint 机制是实现“精确一次”处理语义(Exactly-Once)的基石,确保在故障恢复后,数据既不会被遗漏,也不会被重复计算。
4. 实践与案例:DataStream API 的统一应用
DataStream API 的统一性
自 Flink 1.12 版本起,
DataStream API 通过引入执行模式(Execution Mode)的概念,正式统一了批处理和流处理。开发者可以使用同一套 API,只需在执行前指定不同的模式即可。
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 获取执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 为无界流设置 STREAMING 模式 (默认)
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 为有界流设置 BATCH 模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);案例一:处理无界流(实时热门商品统计)
- 场景描述:从 Kafka 读取用户点击行为数据流,实时统计每分钟点击量最高的前 5 个商品。
- 关键代码逻辑:
// 1. 创建 STREAMING 执行环境
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 2. 使用 Kafka Source 读取无界数据流
DataStream<UserClick> clickStream = env.fromSource(kafkaSource, ...);
// 3. 分配时间戳和 Watermark
DataStream<UserClick> withTimestampsAndWatermarks = clickStream
.assignTimestampsAndWatermarks(
WatermarkStrategy.<UserClick>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, timestamp) -> event.getTimestamp())
);
// 4. 按商品ID分组,开1分钟的滚动窗口,并聚合
DataStream<ItemViewCount> windowedStream = withTimestampsAndWatermarks
.keyBy(UserClick::getItemId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new CountAggregator(), new WindowResultFunction());
// 5. 在窗口结束后,计算 Top-N
DataStream<String> topNStream = windowedStream
.keyBy(ItemViewCount::getWindowEnd)
.process(new TopNHotItems(5));
topNStream.print();案例二:处理有界流(历史销售数据分析)
- 场景描述:读取一个包含全年销售记录的 CSV 文件,计算每个商品品类的总销售额。
- 关键代码逻辑:
// 1. 创建 BATCH 执行环境
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 2. 使用 File Source 读取有界数据集
DataStream<String> csvInput = env.fromSource(FileSource.forRecordStreamFormat(...).build(), ...);
// 3. 使用 map 解析数据,keyBy 按品类分组,sum 计算总额
DataStream<Tuple2<String, Double>> categorySales = csvInput
.map(line -> {
String[] fields = line.split(",");
// a,100.0
return new Tuple2<>(fields[0], Double.parseDouble(fields[1]));
})
.returns(Types.TUPLE(Types.STRING, Types.DOUBLE))
.keyBy(value -> value.f0) // 按品类 (f0) 分组
.sum(1); // 对销售额 (f1) 求和
// 4. 将结果输出到控制台
categorySales.print();5. 架构/系统层面:流批一体的终极优势
重新定义“批处理”
Flink 提出一个革命性的观点:批处理是流处理的一种特例。一个批处理作业,可以被看作是处理一个“有始有终”的特殊数据流。这种从根源上的认知统一,使得 Flink 可以用一套引擎、一套 API 来处理所有数据处理场景。
“流批一体”模型的战略优势
传统处理海量数据的 Lambda 架构需要维护批处理和流处理两套独立的系统,带来了巨大的复杂性和成本。Flink 的流批一体模型则从根本上解决了这些痛点。
- 降低成本
- 一套 API:开发人员只需学习和使用一套 API。
- 一套开发范式:相同的业务逻辑无需重复开发。
- 一套运维体系:只需维护一个计算集群,极大降低了运维的复杂度和硬件成本。
- 提升一致性
- 使用统一的计算引擎和业务逻辑代码,从根本上消除了因实时与离线计算口径不同而导致的结果不一致问题。
- 增强灵活性与效率
- 同一份代码,既可以部署为实时任务处理增量数据,也可以配置为批处理任务来回溯和修正历史数据。这极大地提升了开发迭代效率和业务响应速度。
6. 总结与展望
核心概念回顾
- 有界流与无界流是 Flink 数据处理模型的根本划分,前者对应批处理,后者对应流处理。
- Flink 通过四大技术支柱——时间概念、水位线、状态管理和检查点,构建了一套能够统一处理这两种数据流的坚实基础。

