

弹性分布式数据集
RDD(弹性分布式数据集)是 Spark 的基础抽象:它是只读、不可变的分区化集合,数据分布在集群的不同节点上,可被并行处理。RDD 支持两类操作:
- Transformation(转换):基于现有 RDD 描述新的 RDD(惰性,不立刻执行);
- Action(行动):触发实际计算并返回结果到 Driver(或把结果写出到外部存储)。
这种设计让开发者能用函数式风格表达数据流,而执行引擎则在真正运行前统一优化与调度。
创建 RDD 的常见方式有两种:
- 并行化本地集合(适合小规模样例与测试);2) 引用外部存储的数据集(例如 HDFS、对象存储或任何提供 Hadoop InputFormat 的系统)。示例(PySpark):
rdd1 = sc.parallelize([1, 2, 3, 4, 5])rdd2 = sc.textFile("hdfs:///data/events.log")
在结构化任务上,官方更鼓励使用 DataFrame/Dataset;但在需要精细控制分区、实现自定义算子或处理非结构化数据时,RDD 仍然是“底座”与“逃生舱”。
MapReduce 中的数据共享速度很慢
传统 MapReduce 框架中,跨作业复用数据通常依赖把中间结果落盘到稳定存储(如 HDFS),随后下一个作业再把它们读回内存。每一轮都伴随序列化/反序列化、网络传输与磁盘 I/O,这在需要频繁重复计算或交互分析的场景里会显著拖慢整体效率。学术界早就注意到:MapReduce 对“迭代式算法”和“交互式分析”的支持并不理想,瓶颈就在于内存级数据共享缺位。
MapReduce 上的迭代操作
在多阶段应用程序中,跨多个计算重用中间结果。下图展示了当前框架在 MapReduce 上执行迭代操作时的工作原理。由于数据复制、磁盘 I/O 和序列化,这会产生大量开销,从而降低系统速度
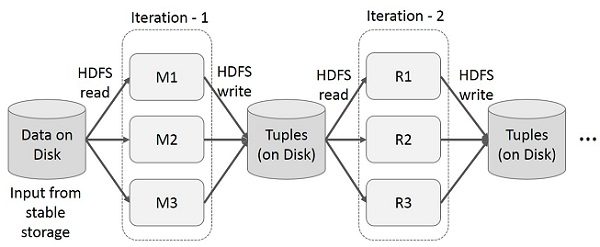
MapReduce 上的交互式操作
交互分析强调低时延:用户对同一数据集发起多次小改动查询,期望“改一次、看一次”。在 MapReduce 体系里,这些临时查询仍要经历读盘→计算→写盘的重流程,哪怕数据子集完全相同,也难以在内存中直接复用先前的结果。因此,交互式任务在该模型下往往响应不够敏捷。
下图说明了当前框架在 MapReduce 上进行交互式查询时如何工作。
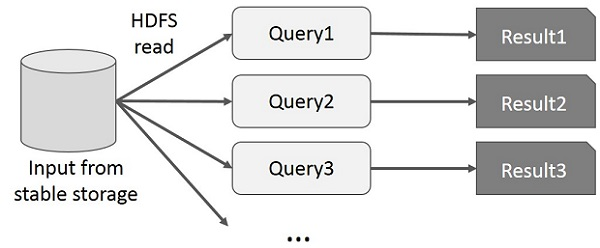
使用 Spark RDD 共享数据
Spark 用 RDD 填上了“内存级数据共享”的空白:
- 惰性构建、按需执行:一连串 transformation 先形成逻辑计划,等到 action 才真正跑起来;
- 显式持久化(cache/persist):把 RDD 的分区保存在 Executor 内存(必要时落盘),供后续 action 直接复用,常能把后续查询加速到数量级级别(取决于数据与算子)。
Spark 用 RDD 填上了“内存级数据共享”的空白:
- 惰性构建、按需执行:一连串 transformation 先形成逻辑计划,等到 action 才真正跑起来;
- 显式持久化(cache/persist):把 RDD 的分区保存在 Executor 内存(必要时落盘),供后续 action 直接复用,常能把后续查询加速到数量级级别(取决于数据与算子)。
在工程上,RDD 的持久化由 StorageLevel 控制:是否驻留内存、是否溢写磁盘、是否序列化、是否副本冗余(如 _2 表示双副本)。在资源紧张时,Spark 会按 LRU 逐出旧分区;必要时也可把存储级别设为 MEMORY_AND_DISK,兼顾速度与稳定。
Iterative Operations on Spark RDD
在迭代式算法里,把中间状态保存在分布式内存是性能的关键:
- 迭代一开始将初始 RDD 持久化;
- 每轮基于上轮结果派生新的 RDD(仍是惰性),行动时直接命中缓存;
- 若内存不足,按存储级别策略选择溢写或淘汰。
此外,Checkpoint 能在必要时截断血缘、把关键中间结果写入可靠存储(如 HDFS),以缩短失败恢复路径、避免极深的依赖链。通常建议先持久化再做 checkpoint,减少物化开销。
下图展示了 Spark RDD 上的迭代操作。它将中间结果存储在分布式内存中,而不是稳定存储(磁盘),从而提高系统速度。
注意 - 如果分布式内存(RAM)不足以存储中间结果(JOB 的状态),那么它将把这些结果存储在磁盘上。
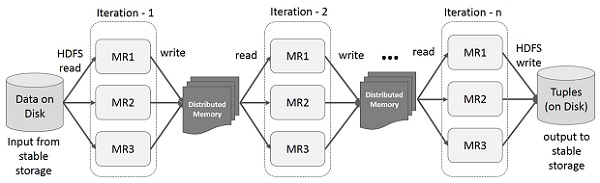
Spark RDD 的交互操作
此图展示了 Spark RDD 上的交互式操作。如果对同一组数据重复运行不同的查询,则可以将这些特定数据保存在内存中,以缩短执行时间。
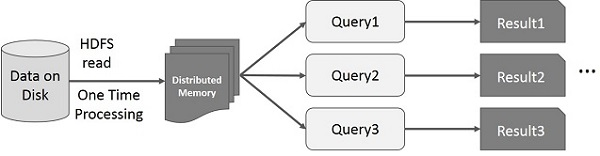
默认情况下,每次对转换后的 RDD 执行操作时,都可能需要重新计算。不过,您也可以将 RDD 持久化到内存中,这样 Spark 会将元素保留在集群中,以便下次查询时更快地访问。此外,Spark 还支持将 RDD 持久化到磁盘上,或将其复制到多个节点上。

