

各行各业都在广泛使用 Hadoop 来分析其数据集。原因在于 Hadoop 框架基于简单的编程模型(MapReduce),能够提供可扩展、灵活、容错且经济高效的计算解决方案。这里主要关注的是处理大型数据集时保持速度,包括查询之间的等待时间和运行程序的等待时间。
Spark 由 Apache 软件基金会推出,用于加速 Hadoop 计算软件的运行过程。
与普遍的看法相反, Spark 并非 Hadoop 的修改版本 ,而且实际上并不依赖于 Hadoop,因为它拥有自己的集群管理。Hadoop 只是实现 Spark 的方式之一。
Spark 使用 Hadoop 的方式有两种:一种是存储 ,一种是处理 。由于 Spark 有自己的集群管理计算,因此它仅将 Hadoop 用于存储目的。
Apache Spark
Apache Spark 是一种闪电般快速的集群计算技术,专为快速计算而设计。它基于 Hadoop MapReduce,并扩展了 MapReduce 模型,以便高效地将其用于更多类型的计算,包括交互式查询和流处理。Spark 的主要特性是其内存集群计算 ,可提高应用程序的处理速度。
Spark 旨在覆盖各种工作负载,例如批处理应用程序、迭代算法、交互式查询和流式处理。除了在各自的系统中支持所有这些工作负载外,它还减轻了维护单独工具的管理负担。
Apache Spark 的演变
Spark 起源于学术研究,对象是如何在分布式集群上高效地进行通用数据计算。早期工作强调把复杂的数据处理链条从“多阶段的固定模式”解放出来,允许以可组合的转换和延迟执行构建计算图。之后,随着社区和工业界的推动,Spark 在几个关键方向上不断成熟:
- 数据抽象的演进:从最初的 RDD 抽象,到引入携带模式信息的 DataFrame/Dataset,使查询优化器能够更深入地理解与重写计算计划。
- SQL 与优化器:Spark SQL 成为结构化数据的核心入口,围绕它形成了以逻辑/物理计划重写、代价估计与代码生成为代表的优化体系。
- 流式计算的统一视角:从早期的 DStream(以 RDD 为基础)过渡到 Structured Streaming,将批处理与流处理统一到 DataFrame/Dataset 语义层。
- 生态扩展:围绕机器学习(MLlib)与图计算(GraphX)等库,Spark 逐步构建出覆盖数据摄取、处理、分析、建模的完整链路。
Apache Spark 的功能
Spark 的主要特性可以概括为以下几个方面:
- 高性能:以内存计算为先,结合列式读写、谓词下推、列裁剪、代码生成等手段,在常见分析任务中具有良好的吞吐和时延表现。
- 易用性:提供 SQL 与 DataFrame/Dataset 的双重接口,既能用接近数据库/数据框的表达方式,又可在需要时回到底层 RDD 进行更细粒度的控制。
- 多语言支持:Scala/Java/Python/R 的 API 让团队可选择最熟悉的语言进行开发与调试。
- 一体化能力:同一执行引擎覆盖批处理、交互式查询、流式处理、机器学习与图处理,降低多系统拼装的门槛与维护成本。
- 部署灵活:可运行在 Standalone、Hadoop 生态(HDFS/YARN)或云原生平台(如 Kubernetes)之上,支持本地磁盘、分布式文件系统和对象存储等多种存储形态。
Spark 部署
Spark 部署有三种方式,如下所述。
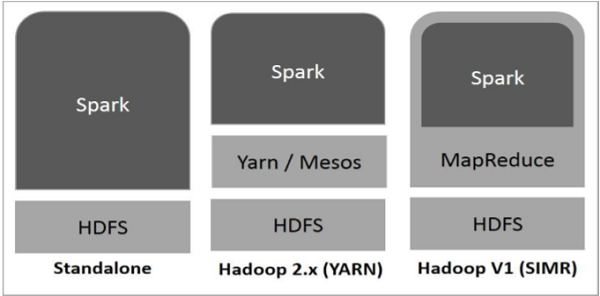
独立 - Spark 独立部署意味着 Spark 占据 HDFS(Hadoop 分布式文件系统)之上的位置,并明确为 HDFS 分配空间。在这里,Spark 和 MapReduce 将并行运行,以覆盖集群上的所有 Spark 作业。- Hadoop Yarn - Hadoop Yarn 部署意味着,简单来说,Spark 可以在 Yarn 上运行,无需任何预安装或 root 访问权限。它有助于将 Spark 集成到 Hadoop 生态系统或 Hadoop 堆栈中。它允许其他组件在堆栈之上运行。
- MapReduce 中的 Spark (SIMR) - MapReduce 中的 Spark 除了独立部署外,还用于启动 Spark 作业。使用 SIMR,用户可以启动 Spark 并使用其 shell,而无需任何管理访问权限。
Spark 的组件
下图描述了 Spark 的不同组件。
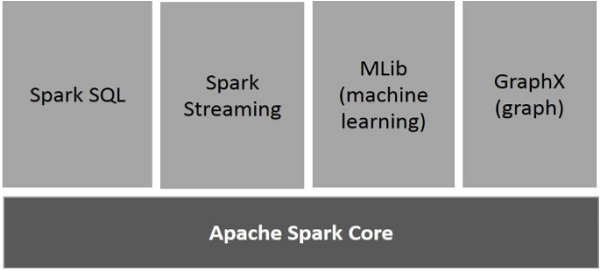
Apache Spark Core
Spark Core 是整个系统的基础,提供任务调度、存储与内存管理、故障恢复以及与集群管理器对接等核心能力。
- RDD 抽象:RDD(弹性分布式数据集)是不可变、分区化的数据集合,通过转换(transformation)与行动(action)来构建与触发计算;血缘信息使得在节点故障时能够按需重算。
- 执行模型:一次行动算子会触发作业划分为多个 Stage,每个 Stage 由多个 Task 并行执行。窄依赖(如 map/filter)通常能在内存中流水化处理;宽依赖(如分组与连接)会引发 Shuffle 和数据重分区。
- 常用机制:缓存/持久化 用于复用热点中间结果;广播变量 可分发小型只读数据(如小维表);累加器 便于收集度量信息。
实践提示:理解分区与依赖关系是性能优化的前提;适度缓存、控制小文件数量、避免无谓的collect()都能带来实际收益。
Spark SQL
Spark SQL 为结构化与半结构化数据提供 DataFrame/Dataset 与 SQL 两种表达方式。由于具备显式的模式(schema),引擎可以执行更深入的优化。
- 优化思路:通过逻辑/物理计划重写、连接顺序调整、列裁剪、谓词下推与整段代码生成等技术减少 CPU 与 I/O 成本。
- DataFrame/Dataset:DataFrame 可看作“带模式的分布式表”,Dataset 在 Scala/Java 环境提供强类型封装;两者与 SQL 可以互相转换,便于在同一作业中混合使用。
- 数据读写:常见的格式包括 CSV、JSON、Parquet、ORC 等;对列式格式可充分利用列裁剪与谓词下推。结合分区列(partitioning)与合理的文件大小策略,可减少全表扫描与元数据开销。
- UDF 与内置函数:优先使用内置函数以便让优化器“看见”计算逻辑;确需 UDF 时需注意序列化与向量化开销。
Spark Streaming
在 Spark 的历史中,Spark Streaming 指早期的 DStream API:它将流式数据离散成连续的小批次,以 RDD 序列的方式处理。随着引擎的演进,社区推出了Structured Streaming,把流式计算提升到 DataFrame/Dataset 层次,实现与批处理统一的编程模型。
- 统一语义:批/流使用相同的变换与聚合,减少心智切换。
- 持续增量处理:引擎会将静态查询“增量化”,根据触发器以微批或近实时模式推进。
- 一致性与状态:结合 checkpoint/事务性 sink、水位线(watermark)与状态算子,可以在吞吐与一致性之间取得平衡。
无论采用 DStream 还是 Structured Streaming,生产中都应关注 checkpoint 位置、输出幂等性与背压控制。
MLlib (Machine Learning Library)
MLlib 是 Spark 的机器学习库,当前以 DataFrame‑based API(spark.ml) 为主,提供从特征工程、模型训练/评估到**流水线(Pipeline)与模型选择(交叉验证/网格搜索)**的一体化工具集。
- 常见算法:分类与回归(逻辑回归、决策树、随机森林、梯度提升等)、聚类(如 K-Means)、推荐(ALS)、降维(如 PCA)等。
- 工程实践:把清洗、特征处理、模型训练和评估封装到同一个 Pipeline 中,便于复现实验与上线部署;对超大数据集,可结合采样、特征选择与合理的并行度控制优化训练成本。
- 与外部生态的配合:可与分布式文件格式、流式输入以及模型持久化工具衔接,形成从数据到模型的闭环。
GraphX
GraphX 针对图数据与图算法提供抽象与实现。它把图表示为包含顶点与边的 RDD 结构,并提供诸如 subgraph、joinVertices、aggregateMessages 等核心算子,以及 Pregel 风格的迭代计算接口。
- 典型任务:PageRank、连通分量、最短路径、社群发现等。
- 使用要点:由于 GraphX 建立在 RDD 之上,性能与易用性与 DataFrame 系列有所差异;在处理高度结构化的图或需要图数据库特性的场景,可评估与专门的图系统搭配使用。

