Spark Core 是整个项目的基础。它提供分布式任务调度和基本 I/O 功能。Spark 使用一种称为 RDD(弹性分布式数据集)的专用基础数据结构,它是跨机器分区的数据的逻辑集合。RDD 可以通过两种方式创建:一是引用外部存储系统中的数据集;二是对现有 RDD 应用转换(例如 map、filter、reducer、join)。
RDD 抽象通过语言集成的 API 公开。这简化了编程复杂性,因为应用程序操作 RDD 的方式类似于操作本地数据集合。
Spark Shell
Spark 提供了一个交互式 shell,一个强大的数据交互分析工具。它支持 Scala 或 Python 语言。Spark 的主要抽象概念是一组分布式数据集合,称为弹性分布式数据集 (RDD)。RDD 可以通过 Hadoop 输入格式(例如 HDFS 文件)创建,也可以通过转换其他 RDD 来创建。
Open Spark Shell 打开 Spark Shell
$ spark-shellCreate simple RDD 创建简单的 RDD
让我们从文本文件创建一个简单的 RDD。使用以下命令创建一个简单的 RDD。
scala> val inputfile = sc.textFile(input.txt)上述命令的输出是
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API 引入了一些转换和一些操作来操作 RDD。
RDD Transformations RDD 转换
RDD 转换返回指向新 RDD 的指针,并允许您在 RDD 之间创建依赖关系。依赖链(依赖关系字符串)中的每个 RDD 都有一个用于计算其数据的函数,并有一个指向其父 RDD 的指针(依赖关系)。
Spark 是惰性的,所以除非你调用某些转换或操作来触发作业的创建和执行,否则不会执行任何操作。请看以下字数统计示例的代码片段。
因此,RDD 转换不是一组数据,而是程序中的一个步骤(可能是唯一的步骤),告诉 Spark 如何获取数据以及如何处理数据。
下面给出了 RDD 转换的列表。
| S.No 序号 | Transformations & Meaning 转变与意义 |
|---|---|
| 1 | map(func) 地图(函数) Returns a new distributed dataset, formed by passing each element of the source through a function func. |
| 2 | filter(func) 过滤器(函数) Returns a new dataset formed by selecting those elements of the source on which func returns true. |
| 3 | flatMap(func) flatMap(函数) Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| 4 | mapPartitions(func) mapPartitions(函数) Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> ⇒ Iterator<U> when running on an RDD of type T. |
| 5 | mapPartitionsWithIndex(func) Similar to map Partitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) ⇒ Iterator<U> when running on an RDD of type T. |
| 6 | sample(withReplacement, fraction, seed) Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| 7 | union(otherDataset) 联合(其他数据集) Returns a new dataset that contains the union of the elements in the source dataset and the argument. |
| 8 | intersection(otherDataset) Returns a new RDD that contains the intersection of elements in the source dataset and the argument. |
| 9 | distinct([numTasks]) Returns a new dataset that contains the distinct elements of the source dataset. |
| 10 | groupByKey([numTasks]) groupByKey([numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Note − If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. |
| 11 | reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V, V) ⇒ V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different from the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| 13 | sortByKey([ascending], [numTasks]) When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the Boolean ascending argument. |
| 14 | join(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called group With. |
| 16 | cartesian(otherDataset) 笛卡尔(其他数据集) When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| 17 | pipe(command, [envVars]) 管道(命令,[envVars]) Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings. |
| 18 | coalesce(numPartitions) 合并(numPartitions) Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| 19 | repartition(numPartitions) Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
行动
下表给出了返回值的操作列表。
| S.No 序号 | Action & Meaning 行动与意义 |
|---|---|
| 1 | reduce(func) 减少(函数) Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| 2 | collect() 收集() Returns all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| 3 | count() 数数() Returns the number of elements in the dataset. |
| 4 | first() 第一的() Returns the first element of the dataset (similar to take (1)). |
| 5 | take(n) 采取(n) Returns an array with the first n elements of the dataset. |
| 6 | takeSample (withReplacement,num, [seed]) Returns an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| 7 | takeOrdered(n, [ordering]) Returns the first n elements of the RDD using either their natural order or a custom comparator. |
| 8 | saveAsTextFile(path) 保存为文本文件(路径) Writes the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark calls toString on each element to convert it to a line of text in the file. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Writes the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop's Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| 10 | saveAsObjectFile(path) (Java and Scala) Writes the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| 11 | countByKey() Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| 12 | foreach(func) foreach(函数) Runs a function func on each element of the dataset. This is usually, done for side effects such as updating an Accumulator or interacting with external storage systems. Note − modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
使用 RDD 进行编程
让我们借助一个示例来了解 RDD 编程中一些 RDD 转换和操作的实现。
例子
考虑一个字数统计的例子 - 它计算文档中出现的每个单词。将以下文本作为输入,并将其保存为主目录中的 input.txt 文件。
input.txt − 输入文件。
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.
按照下面给出的步骤执行给定的示例。
打开 Spark-Shell
以下命令用于打开 Spark Shell。通常,Spark 是使用 Scala 构建的。因此,Spark 程序运行在 Scala 环境中。
$ spark-shell
如果 Spark shell 成功打开,您将看到以下输出。查看输出的最后一行 Spark context available as sc 表示 Spark 容器会自动创建名为 sc 的 Spark 上下文对象。在启动程序的第一步之前,应该创建 SparkContext 对象。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>创建 RDD
首先,我们必须使用 Spark-Scala API 读取输入文件并创建 RDD。
以下命令用于从给定位置读取文件。此处,使用 inputfile 的名称创建新的 RDD。textFile() 方法中作为参数给出的字符串是输入文件名的绝对路径。但是,如果仅给出文件名,则表示输入文件位于当前位置。
scala> val inputfile = sc.textFile("input.txt")
执行字数转换
我们的目标是统计文件中的单词数量。创建一个平面映射,将每行拆分成单词( flatMap(line⇒line.split() )。
接下来,将每个单词作为键读取,其值为 1 ( = )使用 map 函数 ( map(word ⇒ (word, 1) )。
最后,通过添加相似键的值来减少这些键( reduceByKey(_+_) )。
以下命令用于执行字数统计逻辑。执行此命令后,您将看不到任何输出,因为这不是一个操作,而是一个转换;指向一个新的 RDD 或告诉 Spark 如何处理给定的数据。
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);当前 RDD
在使用 RDD 时,如果您想了解当前 RDD,请使用以下命令。它将显示有关当前 RDD 及其依赖项的描述,以便进行调试。
scala> counts.toDebugString
缓存转换
您可以使用 persist() 或 cache() 方法将 RDD 标记为要持久化。在操作中首次计算时,它将保存在节点的内存中。使用以下命令将中间转换存储在内存中。
scala> counts.cache()应用操作
应用某个操作(例如存储所有转换)会将结果保存到文本文件中。saveAsTextFile() 方法的字符串参数是输出文件夹的绝对路径。尝试以下命令将输出保存到文本文件中。在以下示例中,输出文件夹位于当前位置。
scala> counts.saveAsTextFile("output")检查输出
打开另一个终端进入主目录(在另一个终端中执行 spark)。使用以下命令检查输出目录。
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESS
以下命令用于查看 Part-00000 文件的输出。
[hadoop@localhost output]$ cat part-00000Output 输出
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)
以下命令用于查看 Part-00001 文件的输出。
[hadoop@localhost output]$ cat part-00001 Output
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1) 联合国坚持存储
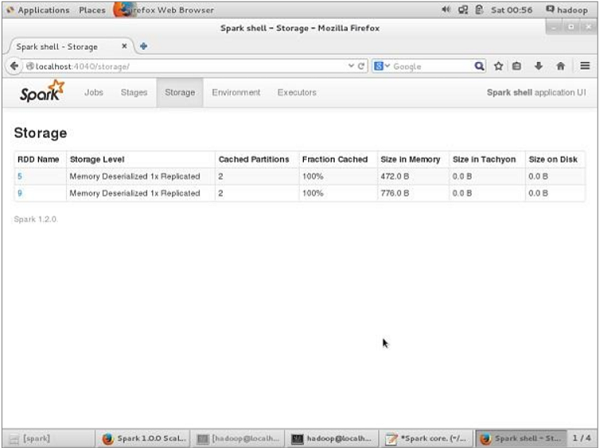
在取消持久化之前,如果您想查看此应用程序使用的存储空间,请在浏览器中使用以下 URL。
http://localhost:4040您将看到以下屏幕,其中显示在 Spark shell 上运行的应用程序所使用的存储空间
如果要取消保留特定 RDD 的存储空间,请使用以下命令。
Scala> counts.unpersist()您将看到如下输出:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14要验证浏览器中的存储空间,请使用以下 URL。
http://localhost:4040/您将看到以下屏幕。它显示在 Spark shell 上运行的应用程序所使用的存储空间。